When Your Team Outgrows Intuition: Building a Delegation Routing Layer

At three team members, you know intuitively who should do what. You hold the routing table in your head. When a task arrives, you match it to a person without conscious effort, because you know their capacity, their skill set, and what they're currently carrying.
At six people across five active client engagements, that intuition breaks.
Not because you become less capable. Because the combinatorics change. Six people, five clients, overlapping leaves and onboarding schedules and escalation rules: the number of valid routing decisions expands beyond what working memory can reliably hold. You start making suboptimal delegation calls. You assign work to people who are at capacity. You brief someone on a task that belongs with someone else. You miss that a new hire shouldn't receive client-facing work in their first week.
This is the problem I designed the SCAN mode for.
The Four-Mode Delegation Architecture
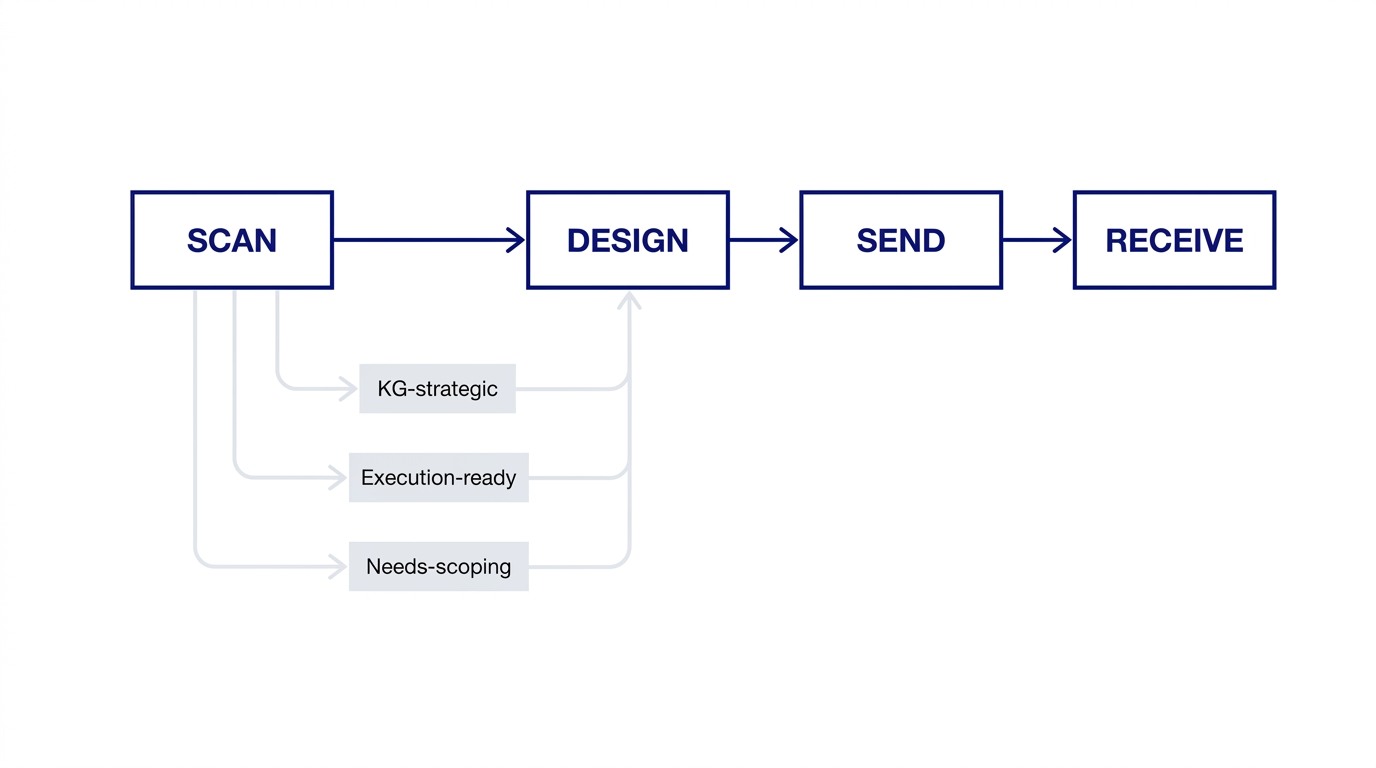
My delegation skill operates in four modes:
SCAN: given a task list, identify what should be delegated, to whom, and in what order. This is the triage layer.
DESIGN: for a selected task, scope the delegation before writing any brief. What is the deliverable? What context does the recipient need? What are the success criteria?
SEND: generate the actual delegation brief, calibrated to the recipient's role and context level.
RECEIVE: when work comes back, evaluate it against the original scope and decide whether to accept, revise, or return it.
Most delegation frameworks stop at SEND. They assume that if you write a clear brief, the system works. That is true only if the triage decision was correct. A well-written brief sent to the wrong person, or sent when the person is at capacity, or sent before the scope is properly defined, produces the same outcome as a bad brief: rework, confusion, and delay.
SCAN is what makes the rest of the architecture work.
What SCAN Actually Does
The SCAN mode reads a task list and produces a delegation shortlist. For each task, it classifies it as:
- KG-strategic: requires KG's judgment, relationship capital, or domain authority. Not delegatable.
- Execution-ready: clear scope, known skill requirement, can be briefed today.
- Needs-scoping: delegatable in principle, but scope is underspecified. Must go through DESIGN before briefing.
For execution-ready tasks, SCAN matches each task to a person by role affinity: who has the relevant skill set? Then it applies capacity constraints: is that person on leave? Are they in their first week? Is this the kind of work that should go through a vendor escalation rather than directly to a team member?
Against a real PEPS Ventures task backlog, SCAN produced this output:
- A relationship follow-up: kept with KG (escalation rule, this is relationship management, not execution)
- New hire onboarding: split across Natasha (physical onboarding) and YT (system training)
- Team member on leave: excluded from all assignments
- UAT assignment: routed to the team member with UAT in their role affinity
- Rental data extraction: routed to the team member in data operations
- PRD review: routed to the team member with product development background
Each of these routing decisions was correct. None of them required my direct involvement to decide. The system held the logic.
The Skill Description Problem
Here is the tension this skill exposed: the skill's intelligence lives in the body of the file. 150 lines of SCAN mode logic covering delegation decision classification, role affinity tables, and capacity rules, but the description field is what determines whether the skill gets triggered at all.
The description field has a 1,024-character limit. That is approximately 150 words. You cannot fit 150 lines of logic into 150 words. So the description has to be written for routing accuracy, not completeness. It needs to match the phrases a user will type when they want delegation help, not explain everything the skill can do.
The resolution: write the description for the front door, not the full house. If someone types "scan my tasks and tell me what to delegate," the skill triggers and the full logic runs. The description does not need to explain the logic. It needs to match the intent.
This is a general principle for any complex skill with rich internal logic. The description field is not a summary. It is a search index.
Eval-First as the Standard
Before shipping SCAN mode, I ran five evaluation cases with seven assertions each, across both the new skill and the baseline. The benchmark: new skill 97% (34/35), baseline 63% (22/35). A 34-percentage-point improvement.
The one failing assertion was in RECEIVE mode Step R5: the instruction to offer saving an evaluation file had a conditional attached ("If no evaluation record exists...") that was easy to skip mid-stream. Fix: make the offer unconditional. A clear, isolated action.
The eval harness is now permanent infrastructure. When the skill needs updating in six months, the harness is already in place to validate the change. The benchmark is the floor.
This is the right way to build skills that matter. Not "does it look right?" but "does it pass the assertions?" For delegation decisions, which involve real people and real task assignments, the quality bar cannot be informal. The benchmark must exist before the skill ships.
Read more on why this matters in The Eval Harness Is Load-Bearing Infrastructure.
What the Architecture Is Actually For
The deeper point behind SCAN mode is cognitive load management.
Every delegation decision that the system holds is a decision that doesn't burn working memory. When I open a briefing session, I am not trying to remember who is on leave, or whether a team member's role affinity includes UAT work, or whether this is a vendor escalation. The system knows. I review the shortlist and decide whether to proceed.
This is not automation for its own sake. It is a way of preserving cognitive bandwidth for the decisions that require judgment. The machine handles the routing table. I handle the calls that require relationship capital, domain expertise, or strategic choice.
At three people, the routing table is trivial. At six, it is not. The SCAN mode is the response to that growth: not more effort, but a different kind of infrastructure.
The skill evolution mirrors the portfolio growth curve. The system you need at scale is not a bigger version of the system you built at the start. It is a different kind of system entirely.
A Note on Parallelism in Eval Design
During the build, I ran two agents in parallel for Evals 4 and 5. Both were independent (SCAN mode vs. multi-person SEND cascade), no shared file writes, separate directories.
Each agent ran both with_skill and without_skill variants rather than splitting them across four agents. This was the correct design. Keeping the comparison in one agent's context produces more coherent grading: the evidence notes reference the contrast explicitly ("with_skill correctly applied the leave exclusion; without_skill missed the team member's status entirely"). Splitting would have produced technically correct but contextually thin grading.
Parallelism is correct when tasks are genuinely independent. Comparative evaluation is not genuinely independent: the comparison requires both sides in the same context. For more on when sequential beats parallel, see Why Sequential Beats Parallel for File-Heavy AI Agent Work.
Part of The Signal's AI Operating System series. Documentation of working patterns from building and operating a Claude Code-based workspace across active consulting engagements.
Strategy and technology are the same decision. Over 15 years in fintech (CTOS, D&B), prop-tech (PropertyGuru DataSense), and digital startups, I have built frameworks that help founders and executives make both moves at once. Based in Kuala Lumpur.
Working on a 0→1 product?
I help founders and operators go from idea to validated product. Let's talk about yours.
Get in touch →