The Eval Harness Is Load-Bearing Infrastructure

There is a threshold in skill development where the question changes from "does this work?" to "does this reliably work?"
The first question is answered by trying the skill and observing the output. The second question cannot be answered that way. One successful invocation does not tell you whether the skill will produce the right output when the input is slightly different, when the user's phrasing varies, or when the context includes an edge case the original author did not anticipate.
The eval harness answers the second question. It is the only mechanism I have found that reliably separates "it worked in my test" from "it works under real conditions."
What an Eval Harness Actually Is
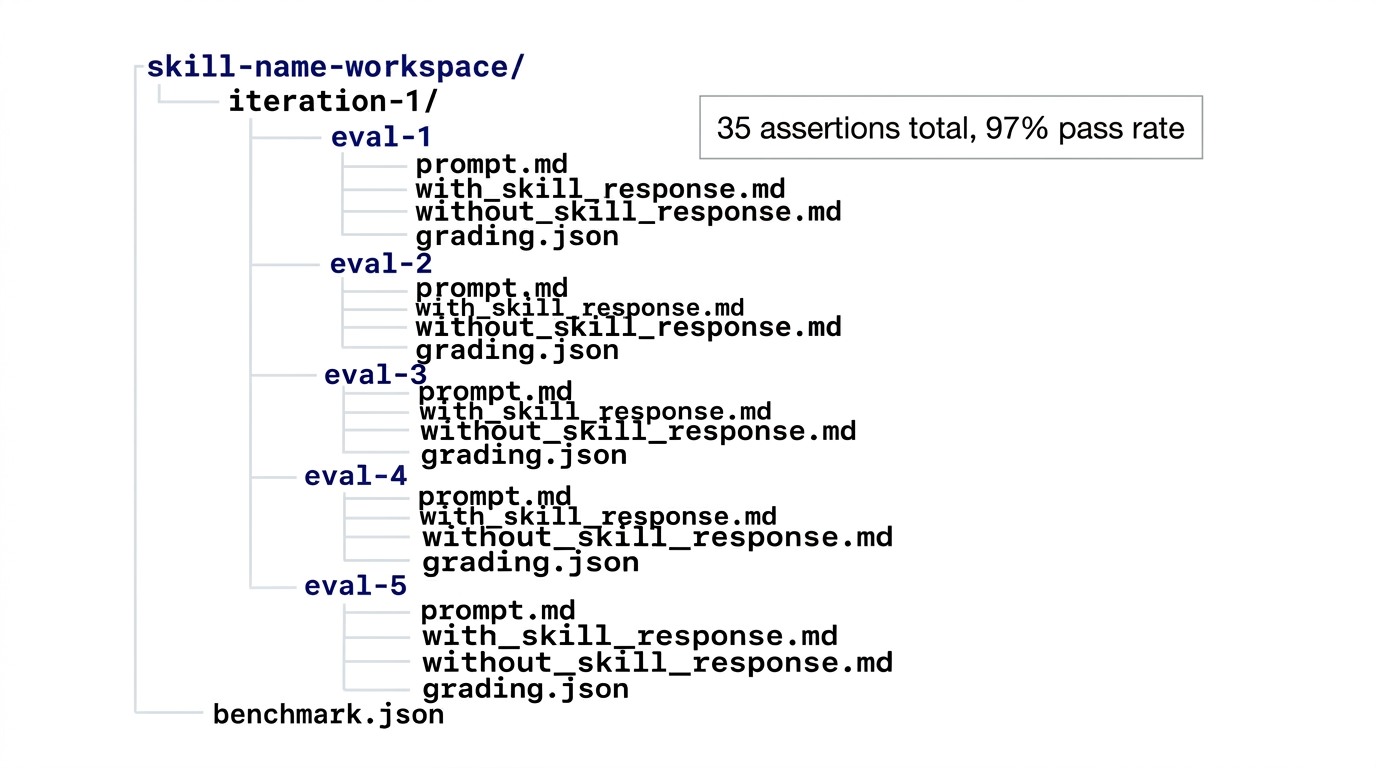
An eval suite for a Claude Code skill is a collection of test cases, each with:
- A defined input (a prompt or scenario the skill should handle)
- A set of assertions (specific claims about what the output must contain or do)
- A grading mechanism (does the output pass each assertion? yes or no)
For the delegation skill I shipped this week, the eval suite covered five scenarios across seven assertions each. Thirty-five total assertion checks. The benchmark: new skill 97% (34/35), baseline 63% (22/35).
The 34-percentage-point lift is the number that matters. Not because it proves the skill is perfect. One assertion still fails, and that is documented as a priority fix, but because it proves the improvement is real and measurable. The benchmark is not a feeling. It is evidence.
The Failure the Evals Found
In RECEIVE mode Step R5, the instruction to offer saving an evaluation file, the original wording was: "If no evaluation record exists for this review, offer to save one."
The conditional is the problem.
When the model reaches Step R5 mid-stream, the reply flow is already nearly complete. The conditional creates an easy exit: if the model believes an evaluation record might exist somewhere, it skips the offer. In practice, it skips it most of the time, because it cannot be certain no record exists.
The fix: remove the conditional. "Always offer to save an evaluation file at the end of every RECEIVE mode session." Unconditional. No escape hatch.
Without the eval harness, this failure is invisible. The skill looks correct in every typical invocation, because typical invocations don't end with the model unsure whether a record exists. The eval harness creates an atypical condition and measures the output. That is where the failure shows up.
The Architecture I Use
Each skill build now produces:
skill-name-workspace/
iteration-1/
eval-1/
prompt.md
with_skill_response.md
without_skill_response.md
grading.json
eval-2/
...
benchmark.json
The benchmark.json aggregates assertion pass rates across all evals for both skill variants. The delta, the percentage-point improvement the skill produces over the baseline, is the headline number.
The grading.json per eval records the evidence notes: not just "pass" or "fail" but why. This is what makes the eval harness genuinely useful for debugging. "with_skill correctly excluded the team member (on leave flag applied); without_skill included her in the shortlist". This tells you exactly where the baseline fails and where the improvement holds.
Why This Matters for High-Frequency Skills
Not every skill needs an eval harness. A skill invoked once a month for a single purpose, where the outputs are reviewed before use, can afford informal quality assurance. The human review is the safety net.
Skills invoked frequently, delegation decisions, meeting notes capture, task classification, do not have that luxury. They are invoked quickly, under time pressure, and often without close review of every output. If the skill has a systematic failure mode, it will appear in production before anyone notices.
The delegation skill will be invoked dozens of times across active engagements. Each invocation produces a routing decision that affects real people and real task assignments. A systematic failure in the leave-exclusion logic, the kind of failure that only appears in edge cases, will surface at scale, not in testing. By then, the remediation cost is high.
The eval harness is the investment that keeps that cost from accruing.
This connects to a principle I described in How I Run 0→1 Product Sprints: ship fast, but wire in the quality feedback loop before you hand off. The eval harness is that feedback loop for AI skills.
The Named Rule
After this week's build, the rule is explicit:
For any skill that touches real people (delegation, briefing, onboarding, task assignment), the eval harness is mandatory before shipping. For skills invoked more than once a week, the harness is mandatory. For everything else, use judgment.
The eval-first discipline is not bureaucracy. It is the difference between "I think this works" and "I measured it working." Those are not the same claim, and they should not be treated as such.
A Note on Eval Design
Running two agents in parallel to grade evals 4 and 5 was the correct architecture. Each agent ran both with_skill and without_skill variants, not one agent per variant. Keeping the comparison in one agent's context produces more coherent grading. Splitting it produces technically correct but contextually thin results.
The practical instruction: when you deploy eval agents in parallel, scope each agent to one test case (or a small cluster), not to one variant. The agent needs to see both sides of the comparison to grade the contrast meaningfully.
This design principle is the flip side of what I cover in Why I Stopped Launching Background Agents for File Creation: parallelism works when the task is genuinely independent. Comparative grading is not genuinely independent. The two variants need to live in the same context.
Part of The Signal's AI Operating System series. Documentation of working patterns from building and operating a Claude Code-based workspace across active consulting engagements.
Strategy and technology are the same decision. Over 15 years in fintech (CTOS, D&B), prop-tech (PropertyGuru DataSense), and digital startups, I have built frameworks that help founders and executives make both moves at once. Based in Kuala Lumpur.
Working on a 0→1 product?
I help founders and operators go from idea to validated product. Let's talk about yours.
Get in touch →