Why I Stopped Launching Background Agents for File Creation

Last Wednesday I ran a 16-hour infrastructure sprint on my AI workspace. The plan was efficient: launch five background agents in parallel, each building a different skill file, then review the outputs an hour later while I worked on something else.
Every single one failed.
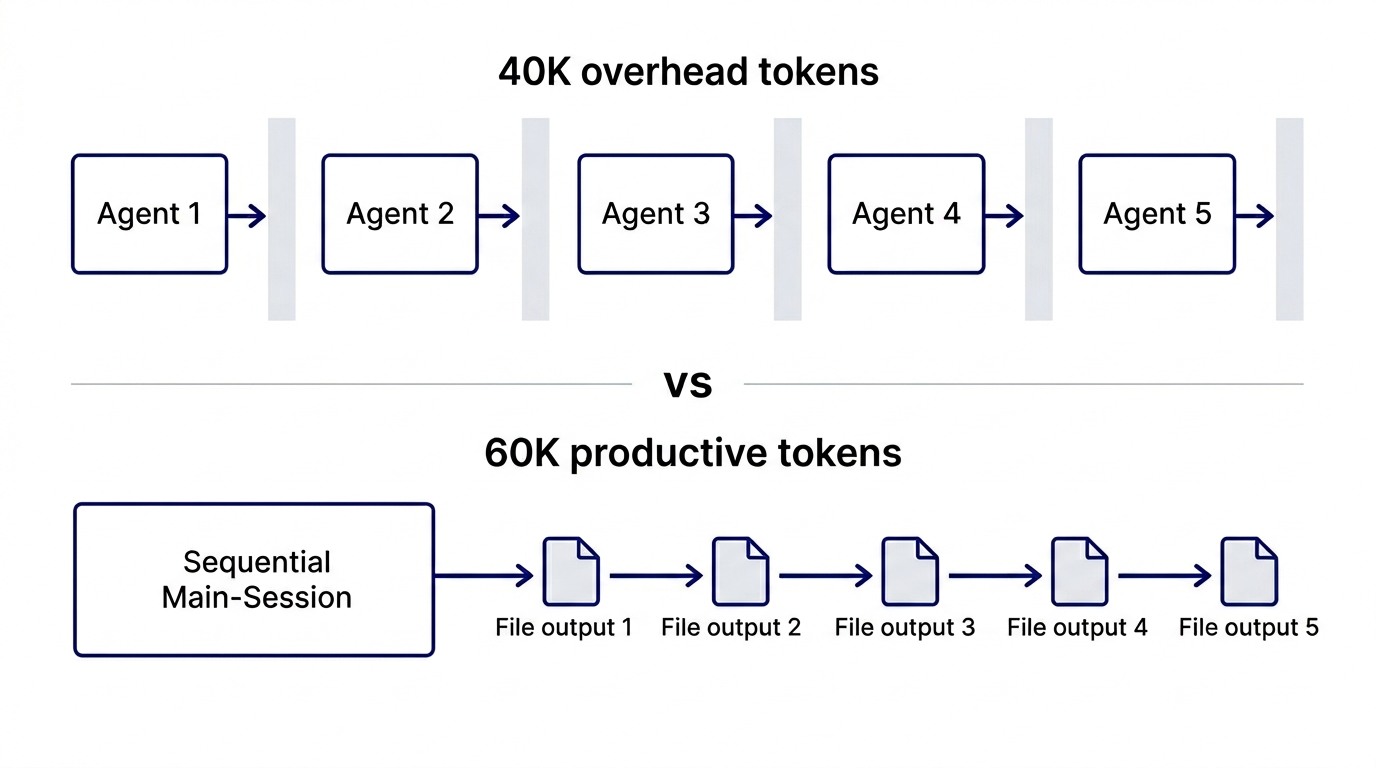
Not a crash. Not an error message. They simply reported back, hours after I had already rebuilt everything manually, that they couldn't do the work. Permission blocks. The Write tool was denied in the agent sandbox. Five agents, zero deliverables, roughly 40,000 tokens burned on coordination overhead.
The sprint still shipped everything it needed to, but it shipped because I did the work sequentially in the main session, not because the parallel architecture worked.
This is the finding I want to document: for file-heavy infrastructure work in Claude Code, sequential execution in the main session is faster and more reliable than parallel background agents. The intuition that parallel is always better is wrong in this context, and the reason is worth understanding.
Why the Failure Happened
The Claude Code agent sandbox does not inherit the parent session's permission grants.
When you run a session in Claude Code and approve a tool, say, the Write tool for a specific directory, that approval is scoped to your current session. Background agents are separate processes. They do not carry your permission grants. When they attempt to create files in directories outside the working tree, the permission wall stops them.
The failure is silent. The agent doesn't crash immediately. It queues up its tool calls, hits the permission block, and reports back when its execution attempt times out. By that point, you've moved on and likely done the work yourself.
The fix is not to adjust permissions or redesign the sandbox. The fix is to stop using background agents for file creation.
What Sequential Actually Costs
In the sprint, I rebuilt all five skill files manually in the main session. The comparison:
Parallel agent attempt (failed): ~40,000 tokens on coordination, zero files produced.
Sequential main session (succeeded): ~60,000 tokens to build all five files, but this included working outputs, no retry overhead, and immediate error detection when something was structurally wrong with a file.
The counterintuitive result: the sequential approach cost more tokens but produced more value. Token count and time-to-value are not the same thing. Parallel agents that fail produce nothing except overhead. Sequential work in the main session produces outputs at a steady rate, allows in-context correction, and keeps the work visible.
There is also a compounding benefit: when you build sequentially, the context from the first file informs the second. The agent writing skill files in the main session could notice a pattern in the first three files and apply a correction to the remaining two. Parallel agents cannot do this. Each one works in isolation.
The Right Use Cases for Background Agents
This does not mean background agents are useless. They are well-suited for:
Research tasks: Reading files, fetching web content, summarizing documents, extracting data from external sources. All of these are read-only operations that don't require Write or Bash permissions. Background agents execute these reliably.
Independent analysis with isolated outputs: Two agents grading the same skill against different test cases, each writing to a separate directory. No shared file writes, no ordering dependencies. This is the architecture I use for eval suites. It works.
Synthesis work: Agents that read many sources and produce a single summary document. Again, the write operation is isolated and scoped to a single deliverable.
The failure mode is specifically: agents that need to create files in shared directories, install things, or execute system commands. These require permission grants that don't propagate to the sandbox.
The Named Rule
After the sprint, I added this to my operating rules:
Background agents: read-only only. Never use background agents for file creation in directories outside the working tree. Build file-heavy infrastructure directly in the main session. Reserve agents for research tasks and isolated analysis with separate output directories.
The rule has a corollary for eval work:
Parallel agents for evals: each agent runs both
with_skillandwithout_skillvariants rather than splitting them across four agents. Keeping the comparison in one agent's context produces more coherent grading, because the evidence notes can reference the contrast explicitly. Splitting produces technically correct but contextually thin grading.
This eval design principle connects to the broader argument in The Eval Harness Is Load-Bearing Infrastructure.
The Broader Pattern
The permission failure revealed something deeper about how AI agent architectures work in practice.
The mental model most people have: more parallel agents equals faster throughput. This is true in distributed computing, where parallelism maps to hardware. It is only conditionally true for AI agents, where parallelism creates coordination overhead and permission isolation.
The more accurate frame: use parallelism when tasks are genuinely independent and share no write targets. Use sequential execution when tasks require shared file writes, ordered dependencies, or system-level permissions. Use agents for research and synthesis, not for installation and configuration.
This week's sprint completed eight of nine planned tasks in approximately 120 minutes of active engagement. The one difference between this sprint and the previous two (both of which had notable waste) was that I worked sequentially in the main session from the start, without attempting parallel agent deployment for file creation. The waste dropped to near zero.
One infrastructure sprint is not proof, but the pattern is strong enough to act on.
What This Means for How I Build
The practical change to my workflow is simple:
- Before deploying a background agent: ask whether the task requires Write or Bash tool use in shared directories. If yes, do it in the main session.
- For eval suites: parallel agents are correct, but each agent must own its full comparison (both variants), not just half of it.
- For infrastructure sprints: use a structured sprint plan with sequential steps. The plan replaces the coordination overhead that parallel agents were supposed to handle.
The third point is the real insight. I was using parallel agents as a substitute for planning. Launching multiple agents simultaneously instead of deciding which task to do first. When I replaced that with an explicit sprint plan (ordered, prioritized, scoped), the sequential approach became just as fast and more reliable.
Infrastructure is not a parallelism problem. It is a prioritization problem.
This connects directly to the revenue-first sequencing described in The 95% Margin Workflow: the order in which you do things matters as much as the things themselves.
Part of The Signal's AI Operating System series. It documents working patterns from building and operating a Claude Code-based workspace across active consulting engagements.
Strategy and technology are the same decision. Over 15 years in fintech (CTOS, D&B), prop-tech (PropertyGuru DataSense), and digital startups, I have built frameworks that help founders and executives make both moves at once. Based in Kuala Lumpur.
Working on a 0→1 product?
I help founders and operators go from idea to validated product. Let's talk about yours.
Get in touch →