The Compounding Agent in Production

Pawel Huryn's framework is correct. Here is what six months of production actually looks like.
Most AI setups are expensive re-derivers.
Each session, the model reconstructs what it already knew last week: the same client context, the same formatting rules, the same procedure for writing a task back to the master file. Nothing persists. Nothing accumulates. You pay for the same work twice, then three times, then indefinitely.
I spent the first three months of working with Claude Code doing exactly this. The setup worked well for individual sessions. It was useless at accumulating anything across them. Every Monday felt like week one.
Then I rebuilt. This is what the working version looks like after six months, including the gaps that still exist.
The Shape of the Setup
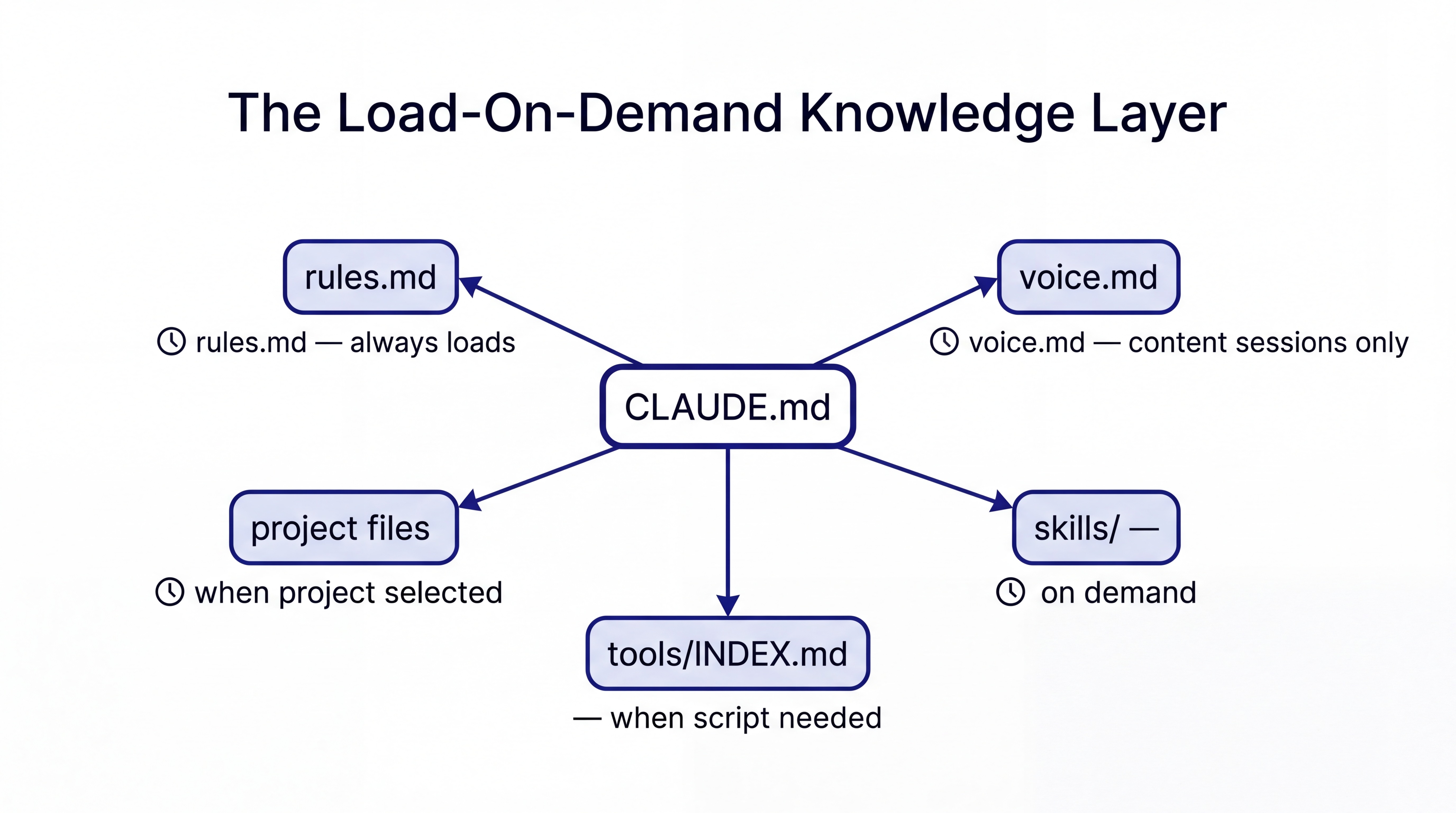
The knowledge layer is bigger than one file and smaller than it sounds.
At the center is an orchestrator file, CLAUDE.md, that loads every session. It is short. Its job is to point to everything else, not to contain everything itself. Most of the actual knowledge lives in files that load on demand: the voice and style guide loads only when the session involves content creation; the client rules load only when that client's project is selected; the research pipeline rules load only when a research task is active.
This is the structural move that makes compounding possible. A fat instructions file that loads everything every session costs thousands of tokens before the first task begins. A routing system that loads only what the current session needs costs a few hundred tokens and leaves the rest of the context window for actual work.
The folder shape that anchors this:
workspace/
├── CLAUDE.md # orchestrator. Always loads, points to the rest
├── rules.md # behavioral rules. Always loads
├── voice.md # style guide. Loads for content sessions only
├── project-{client}/
│ ├── {client}-project.md # open tasks, session log. Loads when project selected
│ └── [deliverables]
├── tools/
│ └── INDEX.md # registry of deterministic scripts
├── metrics/ # session telemetry, knowledge graph
└── .claude/skills/ # skill library. Invoked on demand
The key property: at session start, only the orchestrator and behavioral rules load. Everything else loads when the session needs it.
Principle 1: Portability
Anthropic shipped four remote surfaces in five months. The setups that lived inside one of them started over each time.
The remedy is a single source of truth for the orchestrator, with harness-specific files as thin wrappers. Claude Code reads CLAUDE.md; Codex reads AGENTS.md, which contains a one-line @CLAUDE.md import. The content lives once. Both harnesses consume it.
The test I use: can I switch harnesses in five minutes? If not, the knowledge is hostage to the tool. When your primary tool changes terms, pricing, or architecture, your accumulated knowledge should transfer intact.
This is not a theoretical concern. The sessions where I switched between Claude Code and Cowork cost almost nothing because the orchestrator is harness-agnostic. The sessions where I had context stored in tool-specific memory cost everything.
Principle 2: Determinism
The most expensive failure mode in knowledge layer design is autonomous re-derivation: the model reasoning from scratch about how to do something it has done before.
The remedy is a clean split. Code handles mechanics. Markdown handles judgment.
A concrete example from this workspace: TASK.MD is the master cross-project task registry. Every task that enters or completes writes through that file. Early on, I used the model's Edit tool to modify it. Edits failed intermittently because of a file synchronization issue between the Linux VM running the model and the Windows-side OneDrive copy. The model would re-diagnose the problem every time it appeared, spending tokens on a root cause it had already found.
The fix was a Python script: mark_done.py reads the file, flips the matching task from [ ] to [x], and rewrites the whole file atomically. The Edit tool is now prohibited for TASK.MD. The script handles the mechanics. The rule in CLAUDE.md that says "use mark_done.py for task completion" handles the judgment about when to call it.
The test for whether something should be code: can you describe the step without saying "it depends"? If yes, it should be a script. If the answer requires judgment, keep it in markdown.
Over six months, this split has moved roughly 25 procedures from prose re-derivation to named scripts: task writes, telemetry aggregation, research freshness checks, boundary checks against the daily session budget, manifest rebuilds. Each promotion saves the re-derivation cost on every future call.
Principle 3: Context
Maintaining a knowledge layer manually does not scale. The bottleneck becomes the practitioner's available time.
The remedy is inverting the maintenance ownership. The model maintains the knowledge layer; the practitioner stays on the review path. In practice this means: when the model notices a pattern repeating across sessions, it proposes a rule. When a procedure appears for a second time, it proposes wrapping it as a named script. When a hypothesis accumulates enough evidence across sessions, it proposes promotion to a confirmed rule.
The knowledge promotion pipeline in this workspace has three tiers. Session observations land in a JSONL file. When observations cluster into a pattern, a hypothesis forms in learned-rules.md with an evidence count. When the evidence count reaches three or more, the model flags it for promotion to rules.md, the permanent behavioral rules file, and asks for confirmation.
This is the part of the framework that feels different in practice from how it reads in theory. You are not updating a configuration file. You are managing a colleague who is building their own understanding of how the work runs, one confirmed hypothesis at a time.
Where the Gaps Still Are
After six months, two structural gaps remain.
The first is a unified tools registry. Deterministic scripts were distributed across a dozen skill directories and a system folder, with no single index listing what existed, what it did, and how to call it. When a new session needed to call a known procedure, it either searched across multiple directories or re-derived the procedure from scratch. I closed this gap by building tools/INDEX.md with 11 groups, 35 scripts, and one-line descriptions with call signatures. It took less than an hour. It should have existed from month one.
The second gap is domain knowledge organization. The behavioral rules file is flat. Knowledge about AI tooling, client management, financial analysis, and product strategy all live in the same document. Huryn's framework recommends domain folders with routed knowledge: knowledge/pricing/rules.md, knowledge/competitors/hypotheses.md. This allows loading only the relevant domain's knowledge in a given session, rather than paying for the full file every time. I have not built this yet. It is the next structural improvement.
Both gaps cost more to carry than to close. The tools registry cost tokens in wasted search cycles on every session that needed a script. The flat rules file costs tokens in irrelevant context on every specialized session. Small structural debts compound over hundreds of sessions.
Two Things Worth Doing First
If you are building this kind of setup from the start, two structural decisions have the highest return.
First, make the orchestrator a routing system, not a container. Keep it short. Point to everything else. Build the habit of conditional loading before the instructions file gets fat.
Second, create the tools registry before you need it. Every time a procedure runs twice, put it in a script with a name and a call signature, and register it in the index. The second run is when the pattern is clear enough to capture. The third run is when re-derivation starts costing real money.
The model is not the main variable. What you build around it is where the compounding happens.
Strategy and technology are the same decision. Over 15 years in fintech (CTOS, D&B), prop-tech (PropertyGuru DataSense), and digital startups, I have built frameworks that help founders and executives make both moves at once. Based in Kuala Lumpur.
Working on a 0→1 product?
I help founders and operators go from idea to validated product. Let's talk about yours.
Get in touch →