Brief-then-Fire: A Two-Stage Architecture for AI-Augmented Consulting Workflows

The Named Tension
Most attempts to scale consulting work with AI fall into one of two failure modes. The first is sequential prompt cycling: a single human-AI pair works through twenty deliverables in series, which is faster than fully manual but does not change the unit economics. The second is naive parallelism: dispatch ten AI workers simultaneously, hope for coherent output, and spend the saved time fixing inconsistent results.
The pattern that actually works splits the workflow into two stages. The first stage is cheap, parallel, and produces structured intermediate artefacts. The second stage is more expensive, sequential or compressed-parallel, and consumes those artefacts. I am calling this Brief-then-Fire because the names are accurate to what each stage does and short enough to use in conversation.
This post documents the pattern, its triggers, and the four consulting workflows where I have either applied it or am about to. The case study that prompted this pattern is the 95% margin content engagement.
What Brief-then-Fire Looks Like
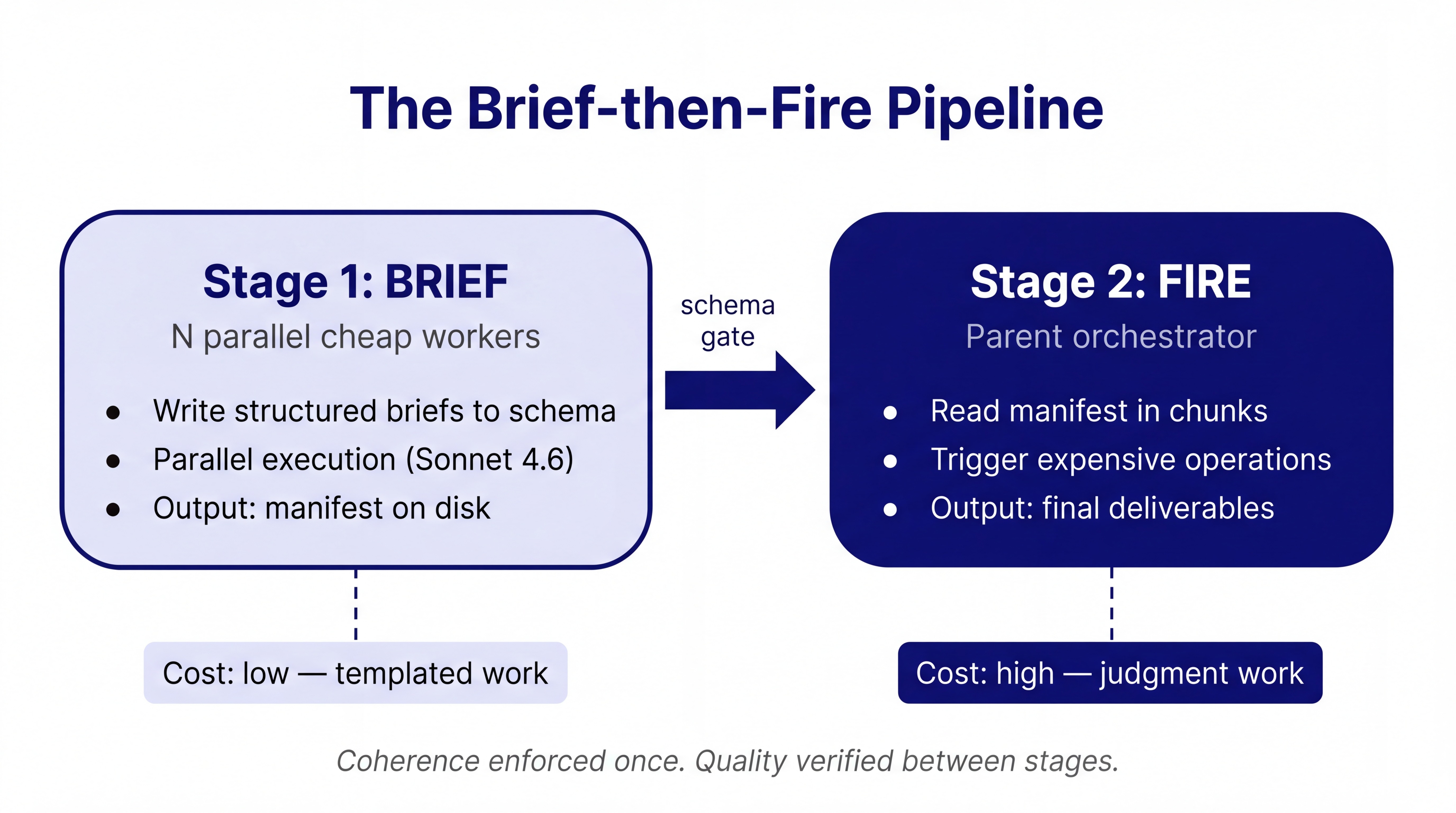
Stage 1: BRIEF
N parallel cheap workers each produce structured prompt briefs to disk
Output: N manifest rows or M JSON files, schema-conformant, voice-checked
Stage 2: FIRE
Parent orchestrator reads chunks of K briefs and triggers expensive operations
Output: Final deliverables (images, documents, API outputs, calculations)
The intermediate artefacts in stage one are not the deliverable. They are the input to stage two. This separation is what makes the workflow scalable.
In the content engineering case I ran last week, stage one was ten parallel Sonnet 4.6 subagents writing 190 image prompt briefs to a JSON manifest. Stage two was the parent agent reading the manifest in chunks of fifteen and firing image generation calls. Total wall time: about ninety minutes for two hundred deliverable images.
Why It Works When Naive Parallelism Does Not
Three things change when you split the work.
Coherence is enforced once, not per worker. The stage one schema is the contract. Every parallel worker writes against the same JSON shape. No worker decides what the output structure should be. The schema lives in one file and gets injected into every dispatch prompt. If the schema needs to change, you change one file.
Verification fits between the stages. Stage one outputs a file on disk. You can grep for em dashes, count rows, validate field types, and reject any worker output that fails the gate. None of this is possible in naive parallelism, where the deliverable is the only output and any defect is already fused into the final state.
Cost efficiency is mechanical. Cheap workers do the templated work. Expensive parents do the sequencing and the high-stakes firing. There is no judgment call about which model handles which stage. The pattern itself enforces the separation.
When to Use It
Brief-then-Fire fits any workflow where:
- The deliverable count is high (more than ten) and the unit work is templated.
- The unit work has a clear schema or input format.
- Quality at the unit level matters and is verifiable from the artefact.
- The expensive operation is the firing, not the briefing.
It does not fit:
- Single-deliverable work (one PRD, one investment memo) where the upfront briefing has no parallelism payoff.
- Work where each unit needs to inform the next unit (sequential dependencies).
- Pure exploratory or strategic work where the schema cannot be specified in advance.
Four Consulting Workflows
The pattern generalises beyond content. Here is where I have either run it or have a credible plan to run it.
Valuation Reports
Stage one: cheap parallel workers extract data from the relevant sources (NAPIC comparables, JPPH benchmarks, audited financials, transaction records). Each worker writes structured findings against a fixed schema: comparable property, transaction date, price per square foot, adjustment factors. Output is a JSON manifest of evidence rows.
Stage two: parent orchestrator reads the manifest and writes the narrative, applies the methodology (cost approach, market approach, income approach), and assembles the IVSC-compliant report.
The split eats the most repetitive part of valuation work, which is evidence gathering and tabulation. The judgment work, which is methodology selection and narrative reasoning, stays with the parent.
ISMS Gap Assessments
Stage one: cheap parallel workers each take a control domain (Access Control, Cryptography, Asset Management, Threat Intelligence) and check the client's existing policy library against ISO 27001:2022 requirements. Output is a structured gap manifest: control reference, requirement summary, current evidence, gap classification (none, minor, major, missing).
Stage two: parent orchestrator reads the gap manifest, prioritises remediation, drafts the recommended remediation steps and timeline, and assembles the ISMS gap assessment report.
I am about to run this on a current engagement. The estimated time saving against my current sequential workflow is roughly 60%, with quality at parity because the schema enforces consistency that I currently rely on memory for.
PRD Generation
Stage one: cheap parallel workers extract user stories from interview transcripts, support tickets, and existing product documentation. Each worker writes against a story schema: user role, action, intent, acceptance criteria, priority signal. Output is a manifest of stories per source.
Stage two: parent orchestrator deduplicates stories, groups them by feature, sequences them by priority, and writes the PRD.
This is the workflow I run for the PaymentXchange and ValuationXchange product lines. The PRDs that result are tighter than my hand-written ones because the story extraction is more exhaustive than I would do alone.
Investment Memos
Stage one: cheap parallel workers each research one dimension of the target company (market sizing, competitive landscape, regulatory exposure, financial performance, leadership team, technology stack, customer concentration). Output is a per-dimension brief against a fixed structure.
Stage two: parent orchestrator reads all dimension briefs, weighs them, identifies the load-bearing thesis, and writes the memo.
This is on my list for the next M&A advisory engagement. The pattern means I can credibly produce a defensible memo in two days that would currently take six.
The Pilot-then-Bulk Companion Discipline
Brief-then-Fire works best when paired with a deliberate pilot. Before dispatching ten parallel workers and firing two hundred operations, run the pattern at 5% scale. One worker, twenty briefs, ten firings. Inspect the manifest. Inspect the output. Adjust the schema or the prompts. Then run the bulk.
The pilot cost is 5% of the bulk. The cost of skipping the pilot and discovering a schema defect at 100% scale is a full re-run, which is 100% waste. The arithmetic is unforgiving and the discipline is cheap.
In the content engineering case, the ten-image pilot caught a manifest field naming defect that would have multiplied across all two hundred bulk images. The pilot saved roughly thirty thousand tokens of rework and prevented the embarrassment of a defective deliverable.
The Schema Is the Hardest Part
The pattern's success depends entirely on the stage one schema. If the schema is loose, parallel workers produce inconsistent output and stage two becomes a deduplication and reformatting exercise. If the schema is too tight, workers produce sterile output that fails to capture the actual nuance of the source material.
Two heuristics that have held up across the four workflows above:
Anchor the schema to the downstream consumer. The stage two operation determines what stage one needs to produce. If the parent will write a narrative valuation report, stage one needs free-text adjustment rationales, not just numeric adjustment factors. If the parent will fire image generation calls, stage one needs structured prompt fields with explicit voice anchors.
Inject the schema verbatim into every dispatch prompt. Do not reference it by file path. Workers approximate when given a path; they conform when given the actual schema text. The token cost of inline injection is trivial compared to the cost of cleaning up inconsistent output.
What This Pattern Replaces
Brief-then-Fire replaces three older patterns I used to rely on:
Single-thread sequential prompt cycling. Slower, more expensive per deliverable, no parallelism payoff. Useful only when the deliverable count is small and the work is genuinely judgment-heavy.
Naive multi-agent dispatch. Faster but coherence-fragile. Each worker decides its own output structure. The merge step takes longer than the production step. Quality is uneven.
Manual templating then prompt-by-prompt execution. This is the pre-AI workflow. Fine for small batches. Crushes you at any scale.
The pattern is not new in software. The MapReduce shape has been around for two decades. What is new is its application to consulting deliverables where the unit work was previously assumed to require human judgment at every step. The honest finding is that most consulting unit work is templated and can be routed through stage one, leaving the genuinely judgment-bearing assembly to the parent.
What to Watch
Two failure modes to monitor.
Stage one becomes a mini-deliverable. When the intermediate manifest starts being read and reasoned over by the client or by you outside the pipeline, the schema needs to harden. Otherwise you end up maintaining two artefacts and the manifest drifts from the deliverable.
Stage two parent runs on the wrong model. I made this mistake last week. Using Opus 4.7 as the parent for bulk firing wasted roughly 60% of the firing-stage spend. The orchestration logic is mechanical and does not benefit from Opus's reasoning depth. Sonnet 4.6 or even a script is the right answer for the firing phase. Match the model to the cognitive demand, not to the workflow's overall importance. The model selection rule is worth reading alongside this.
Closing
The pattern has a name now. The next step is to encode it in a skill so I do not re-derive it engagement by engagement. Within four weeks I expect to be running Brief-then-Fire on three of the four workflows above as standing infrastructure rather than bespoke architecture. The compounding payoff comes from running the same pattern across many engagements, not from running it once spectacularly.
The 95% margin in the content engineering case was not magic. It was Brief-then-Fire plus pilot-then-bulk plus a clean model selection rule. Strip the marketing layer off any productised AI workflow and that is roughly what you find.
Strategy and technology are the same decision. Over 15 years in fintech (CTOS, D&B), prop-tech (PropertyGuru DataSense), and digital startups, I have built frameworks that help founders and executives make both moves at once. Based in Kuala Lumpur.
Working on a 0→1 product?
I help founders and operators go from idea to validated product. Let's talk about yours.
Get in touch →