The Auto-Research Stack: From Karpathy's Experiment to Production Pipelines

Four years ago, Andrej Karpathy described a deceptively simple experiment. Take a code change. Run it against a fixed benchmark. If the metric improves, keep it. If not, revert. Repeat indefinitely. No human in the loop. No interpretation. Just: change, measure, decide, iterate.
He was building ML training code. The agent would propose architectural tweaks, novel initialization schemes, loss function variants. Each one evaluated against the same standard. Over weeks, the code improved. The agent had learned what worked.
That experiment lived in a research memo. Nobody expected it to spread.
Today, the pattern is everywhere. It moved from neural network training into inference optimization. Then into skill improvement. Then into scientific discovery. Then into knowledge workers' pipelines. Each domain discovered it independently. Each time, the lesson was identical: if you can measure it, you can make it improve itself.
For one-person companies and knowledge teams operating at the edge of resources, this changes everything.
The Field Converges
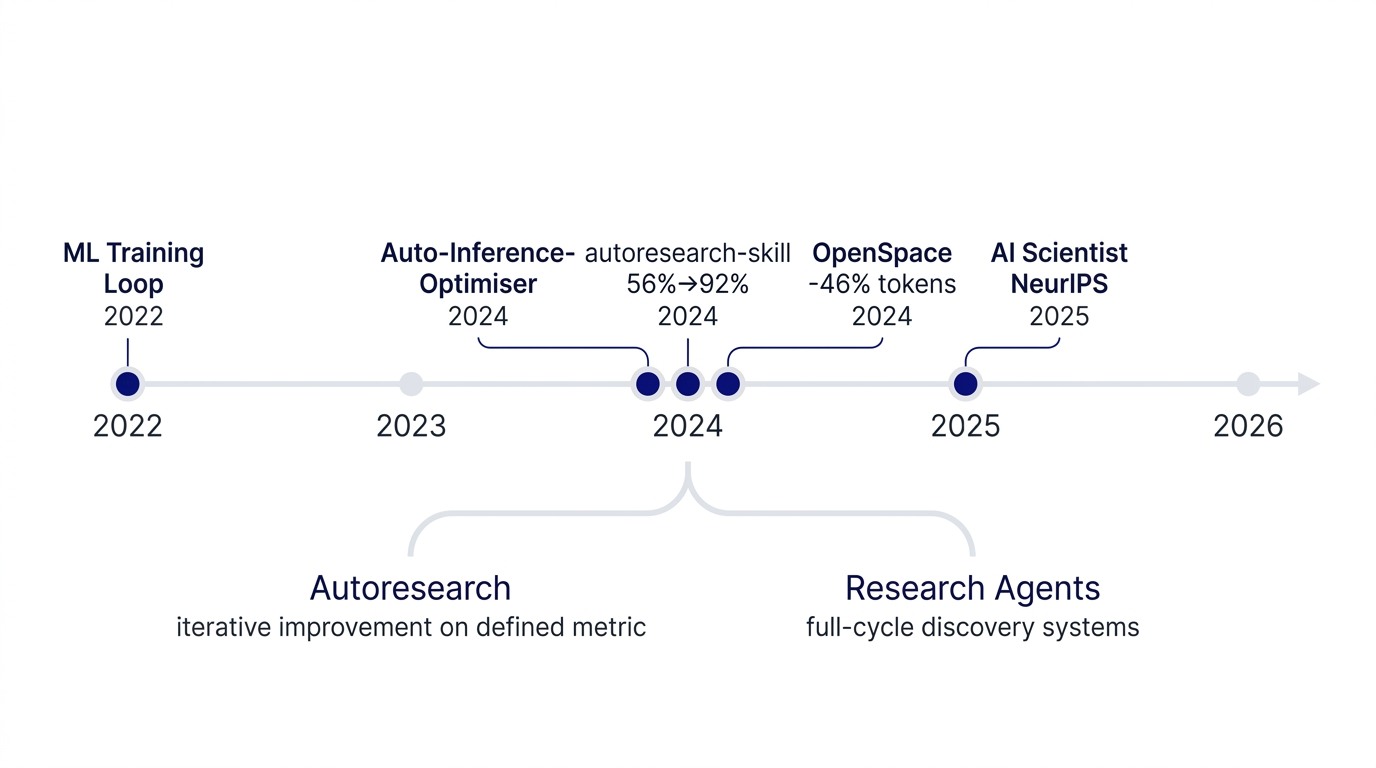
The evidence is dense enough now to see the shape of it. In 2024, a published Auto-Inference-Optimiser reduced Apple Silicon inference latency by percentages that matter for production. An autoresearch skill took Claude prompt templates from 56% performance to 92% across 4 refinement cycles. OpenSpace (from Hong Kong University) demonstrated a cloud-native skill evolution system that cut token consumption by 46% on a standardised benchmark while multiplying economic value 4.2 times.
These are not one-offs. They are not artisanal.
The awesome-autoresearch catalog on GitHub has grown into a formal taxonomy. The inventory now distinguishes autoresearch (iterative improvement on a defined metric) from research agents (full-cycle discovery systems that generate hypotheses, run experiments, produce manuscripts). The same pattern. Different scope.
The catalog entries span: general-purpose improvement loops (works on any task with a metric), full scientific discovery systems (SakanaAI's AI Scientist, which won best paper at NeurIPS 2025 by designing novel ML architectures through autonomous experiment), platform-specific ports, and domain-specific adaptations in chemistry, biology, law, writing, and game design.
What is striking is not the diversity. It is the unanimity. Every team that scaled a knowledge system to production discovered the same law: static pipelines degrade.
The pipeline that finds information should also be the pipeline that improves its own ability to find information.
The world changes. The rules change. The data distribution shifts. The metrics slip, but the moment you equip a system with a measurement standard and an iteration loop, it learns. It drifts less. It compounds.
A Production Pipeline Made Visible
Consider how a content creator research workflow fires at scale. A single command triggers architecture: three subagents deploy in parallel. One agent scans emerging signals for trend. One maps the competitive terrain. One generates rough content ideas. Each operates against a structured template. Each evaluates its own output for quality and completeness. Within 8 minutes, three polished deliverables land in the creator's hands.
The mechanism is simple. A persistent context file holds the editorial voice, the audience definition, the publication goals. When the workflow triggers, subagents load that context as a standard. They measure their output against it. They refine. They converge.
That architecture mirrors my own research intake pipeline, but extended across different tools. WhatsApp messages arrive. kg-research-inbox parses them: extracts entities, classifies signal quality, deduplicates. kg-fetchcontent enriches each signal with full-text content from linked URLs. kg-research-digest synthesizes across 30 to 60 signals in a single pass, finding clusters, identifying overlooked contradictions, surfacing second-order patterns. kg-km turns the digest into publishable knowledge: blog posts, frameworks, advisory narratives.
It is industrial-strength intake. The throughput is measurable. The latency is low. The fidelity is high.
But here is the vulnerability: the pipeline that filters 60 research items down to 12 publishable insights operates on rules written once and not re-examined. The ranking heuristics are static. The synthesis model is frozen. The output templates are fixed.
The pipeline is a research agent. It discovers information, enriches it, organizes it, reports it. It is not an autoresearch system. It does not measure its own performance. It does not improve itself.
The Missing Loop
Here is the tension: everyone is building research agents. Almost nobody is applying the autoresearch pattern to the research pipeline itself.
What would that look like?
Imagine the same intake pipeline, but with one addition. At the end of the synthesis step, measure against a standard. The standard could be: Did the published article generated from this digest get read? Did readers act on it? Or: When domain experts rate signal-to-noise in the original digest, how high is the score? Or: When we re-surface these items six months later, how many predictions in the digest proved true?
Measure it. Capture the metric. Now you have a baseline.
In the next cycle, change one element. Perhaps the ranking heuristic. Perhaps the clustering algorithm. Perhaps the prompt that says "synthesize these 60 signals into 12 insights." Keep the change if the metric improves. Revert if it does not. Do this once per week. Do it automatically.
Over 12 cycles, the pipeline has learned what works. The ranking improves. The synthesis sharpens. The insights compound in value. The machine that discovers information now also knows what kind of discovery its audience acts on.
For a one-person operation, this is structural advantage. For a knowledge team, this is competitive moat.
The principle extends everywhere. A customer research agent can learn which interview questions yield the most actionable insights. A competitive intelligence pipeline can learn which sources predict market shifts earliest. A content synthesis system can learn which narrative framings resonate most deeply. A proposal generation tool can learn which messaging closes more deals.
The pattern is always the same: measure, iterate, improve. Rinse. Repeat.
The Compounding Effect
When you build systems that improve themselves, time becomes an investment instead of an expense.
The first version of your research pipeline extracts 12 insights from 60 signals. It is adequate. You publish. Six months later, the version from month six extracts better insights because it has measured itself 26 times and learned what works. One year in, the learning curve has compounded. The pipeline is not the same system anymore. It is stronger.
Most knowledge workers treat their tools as permanent once built. A research template is good enough, so it remains unchanged. A synthesis process works, so it calculates the same way every cycle. A decision heuristic is reasonable, so it persists, but reasonable compounds into degraded. Static compounds into obsolete. The world never stands still, and neither should your tools.
The autoresearch pattern says: build the system to evolve. Measure what matters. Iterate on what can improve. Let the tools do the work of getting better.
For people building companies alone or in small teams, this is the difference between drowning in volume and gaining on it. It is the difference between tools that feel increasingly constraining and tools that grow alongside your ambition.
The insight is not new. Karpathy's experiment was always obvious in hindsight, but obvious is not the same as applied. The gap between what we know about iteration and improvement and what we actually build into our knowledge systems is still vast.
That gap is closing, and in closing, it is giving back to individuals what scale used to monopolize: the ability to build systems that learn, measure, and improve themselves.
The 95% Margin Workflow covers the operating leverage side of this equation. Once your research pipeline compounds, the next constraint is usually output production, and the Token Economy as Cash Economy framework helps you decide where to spend compute as the system scales.
Strategy and technology are the same decision. Over 15 years in fintech (CTOS, D&B), prop-tech (PropertyGuru DataSense), and digital startups, I have built frameworks that help founders and executives make both moves at once. Based in Kuala Lumpur.
Working on a 0→1 product?
I help founders and operators go from idea to validated product. Let's talk about yours.
Get in touch →