Three Layers Every AI Agent Stack Needs: Memory, Routing, Execution

I have been watching an interesting pattern emerge across three separate practitioners building AI agent systems, and they all arrived at the same architecture independently.
None of them started with this structure. It evolved.
The pattern has three layers: Memory, Routing, and Execution.
Memory: The System's Identity
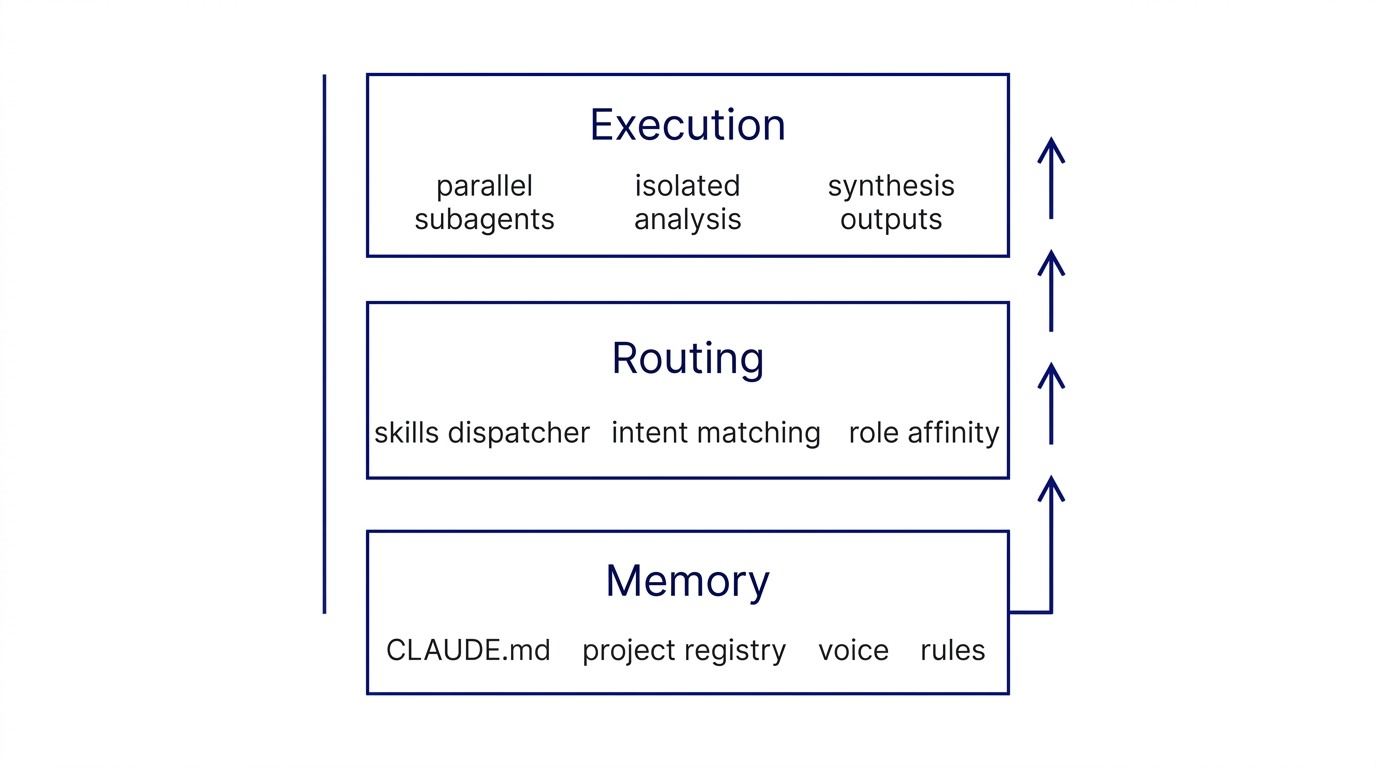
Memory is where the system lives. For me, it is CLAUDE.md plus a unified project registry: voice, rules, file routing, cross-project context all in one place. For other practitioners, it is a Notion workspace with categorized document types. Memory is not data. It is the operational identity of the agent. When someone asks "why does the system respond that way?" the answer lives here.
Memory answers the question every AI system eventually has to answer: what is consistent across sessions? The model forgets. The memory does not. Every rule, every voice guideline, every routing convention is a deposit into the memory layer. Something that does not have to be reconstructed each time.
The mistake most builders make early: treating memory as a log (what happened) instead of as identity (what the system is). Logs are useful. Identity is load-bearing.
Routing: The Dispatch Layer
Routing is the dispatch layer. This is where individual skills become a coherent system. I use 20+ skills, each one a single-purpose tool: kg-research, kg-km-weekly, kg-fetchcontent. The routing layer translates intent, what the user is trying to do, into the correct skill invocation.
One model, infinite tasks, finite attention. Routing solves the impossibility of generality. Without routing, you are solving for a model that can do everything adequately. With routing, you are solving for fit: the right tool for the specific task.
This is the same principle that governs good product design. A product that tries to do everything is worse than a focused product at each specific job. The routing layer is what lets a single AI system behave like a collection of focused tools, each excellent at one thing.
The routing description problem I wrote about in the delegation routing layer post is a specific instance of this: the description field is not documentation. It is a search index. Write it for routing accuracy.
Execution: Where Work Actually Happens
Execution is parallel processing. Subagents process research batches. Automated feeds run. Specialized processors operate in parallel. Not more work: the right work, in the right order, by the right agent.
The pattern here is not about doing more work. It is about doing the right work at the appropriate scope. Parallel subagents for research and synthesis. Sequential execution in the main session for file creation and system changes. The decision tree I covered in Why I Stopped Launching Background Agents for File Creation is the execution layer's operating rule.
Practitioners who have wired this correctly report dramatic time compression. Three structured deliverables in under 8 minutes instead of three hours of back-and-forth. That compression does not come from a better model. It comes from an execution layer that knows which agent to use for which task.
What Is Actually Commoditizing
Individual skills are commoditizing. Anyone can write a skill that fetches content or formats markdown. The setup cost is low. The skill is not the differentiator.
The competitive advantage lives in how skills compose into pipelines. A well-designed pipeline that routes correctly, executes efficiently, and remembers what it learned is harder to replicate than any individual skill.
This maps to something I have observed in product work: the moat is never the feature. It is the system around the feature: the defaults, the integrations, the accumulated context that makes the feature useful rather than merely functional. The same logic applies here.
The model matters less than the architecture around it.
Why This Pattern Converged
Three independent builders. Three different domains. Same three-layer pattern. This stopped being experimental by early 2026.
The convergence happened because the problem is the same for everyone: one model, infinite tasks, finite attention, sessions that forget. Memory, Routing, and Execution are the three solutions to that problem, arrived at by anyone who pushes the system far enough.
The optimization question has shifted. It is no longer "can the model think long enough?" It is "can the model think in a way that sustains effective action?" The answer is architecture, not capability.
If you are building agent systems, check whether your stack has all three layers. Missing one breaks the whole thing. Missing memory means every session starts from scratch. Missing routing means generality beats fit. Missing execution design means throughput does not improve even as you add more tools.
For how this plays out in a specific product context, see How I Run 0→1 Product Sprints: the same three-layer pattern applies when you are building a product intelligence system rather than a personal one.
Part of the Business Process Intelligence series from KG Consultancy. First published March 2026.
Strategy and technology are the same decision. Over 15 years in fintech (CTOS, D&B), prop-tech (PropertyGuru DataSense), and digital startups, I have built frameworks that help founders and executives make both moves at once. Based in Kuala Lumpur.
Working on a 0→1 product?
I help founders and operators go from idea to validated product. Let's talk about yours.
Get in touch →