Hybrid SQL+Vector Search: The Architecture Behind Trustworthy AI Valuations

Property valuation is not a pure technical problem. It is a technical problem constrained by regulation, profession, and judgment.
A valuer in Kuala Lumpur must follow LPPEH guidelines. The guidelines specify that comparables must meet hard criteria: same property type, same submarket, transaction within a specific date window, adjusted for material differences. These are not suggestions. They are enforceability requirements. An appraisal that violates them is indefensible, regardless of how sophisticated the comparable selection methodology is.
At the same time, regulation alone is insufficient. A set of ten comparable properties that technically meet LPPEH criteria might not truly represent the market your subject property operates in. What if a major new development launched in the adjacent submarket three months ago, pulling pricing upward? What if one comparable is an outlier transaction (distressed sale, corporate deal at below-market terms)? Regulation constrains the search space. Judgment navigates within it.
Here is the tension every valuation AI system must resolve: the software must be both precise (it must follow the rules) and intelligent (it must understand market context). These seem to require different tools. Pure SQL search is precise but not intelligent. Pure vector search is intelligent but not precise. Most vendors pick one and call it done.
The hybrid architecture resolves both constraints in a single query. SQL enforces the rules. Vector finds meaning within those rules.
The Vector Search Promise
Vector search (semantic similarity) arrived with tremendous promise. The idea was intuitive: convert properties into high-dimensional vectors, embed them in semantic space, search for nearest neighbors, and return the most similar comparable properties.
It works beautifully for unstructured text. Google embeds documents as vectors. It embeds your query. Nearest neighbors in semantic space are typically the most relevant results.
Property data seemed like a natural fit. Embed historical comparable transactions as vectors. Embed the subject property. Find the nearest ten neighbors. Return those as comparable sales.
Except it does not work that cleanly.
A vector represents a property in semantic space. The embedding learns patterns: properties that sold recently in the same postcode cluster together; properties with recent price growth cluster together; large properties cluster together. The vector captures those patterns.
But what clusters together is not always what is comparable.
Consider a concrete example. You have a shopping mall in Klang. Recently sold. Strong price growth (new anchor tenant, strong foot traffic). You embed it. Now you search for comparable properties. The vector database returns the nearest neighbors. One of them is a residential apartment in Selangor: also recently sold, also with recent price growth, also similar in built-up area.
The vector algorithm says: "Similar prices, similar growth patterns, similar size, similar time. These are neighbors."
You cannot use that comparable. LPPEH does not allow mixing commercial and residential properties. The regulation exists because they operate in different markets with different risk profiles, different income dynamics, and different regulatory treatment.
Vector search did not care. The embedding model learned from historical correlations. It did not learn regulatory definitions. To the algorithm, a comparable that is semantically similar but factually incomparable is still a neighbor.
This is the precision problem. Vector search optimizes for semantic similarity. It does not optimize for regulatory correctness.
The SQL Search Constraint
SQL search is the opposite problem.
You write a query: select all properties where property_type = "shopping mall" and postcode_submarket = "klang" and transaction_date > (today - 6 months) and land_area between 4000 and 8000 and price between 8m and 20m.
This query is bulletproof. Every result meets LPPEH criteria. You can cite the query in your appraisal report. The regulator can audit it. You can defend it.
But here is what you miss.
The query returns twelve comparable properties. All technical matches. But one of them is an outlier: it sold under distressed terms (owner bankruptcy, forced liquidation). The price is artificially low. It does not represent the market.
Another comparable sold six months ago, just before a major anchor tenant signed a new lease. The market dynamics have shifted. The comparable is no longer representative of current market rates.
A third comparable is technically in the same submarket, but it is separated from your subject property by a major highway. Foot traffic patterns are different. Price dynamics are different.
SQL returns all three. SQL does not know they are outliers. SQL knows they match the criteria.
This is the recall problem. SQL optimizes for precision (every result matches the criteria). It does not optimize for market sense (is this result truly representative of my subject's market?).
The Hybrid Resolution
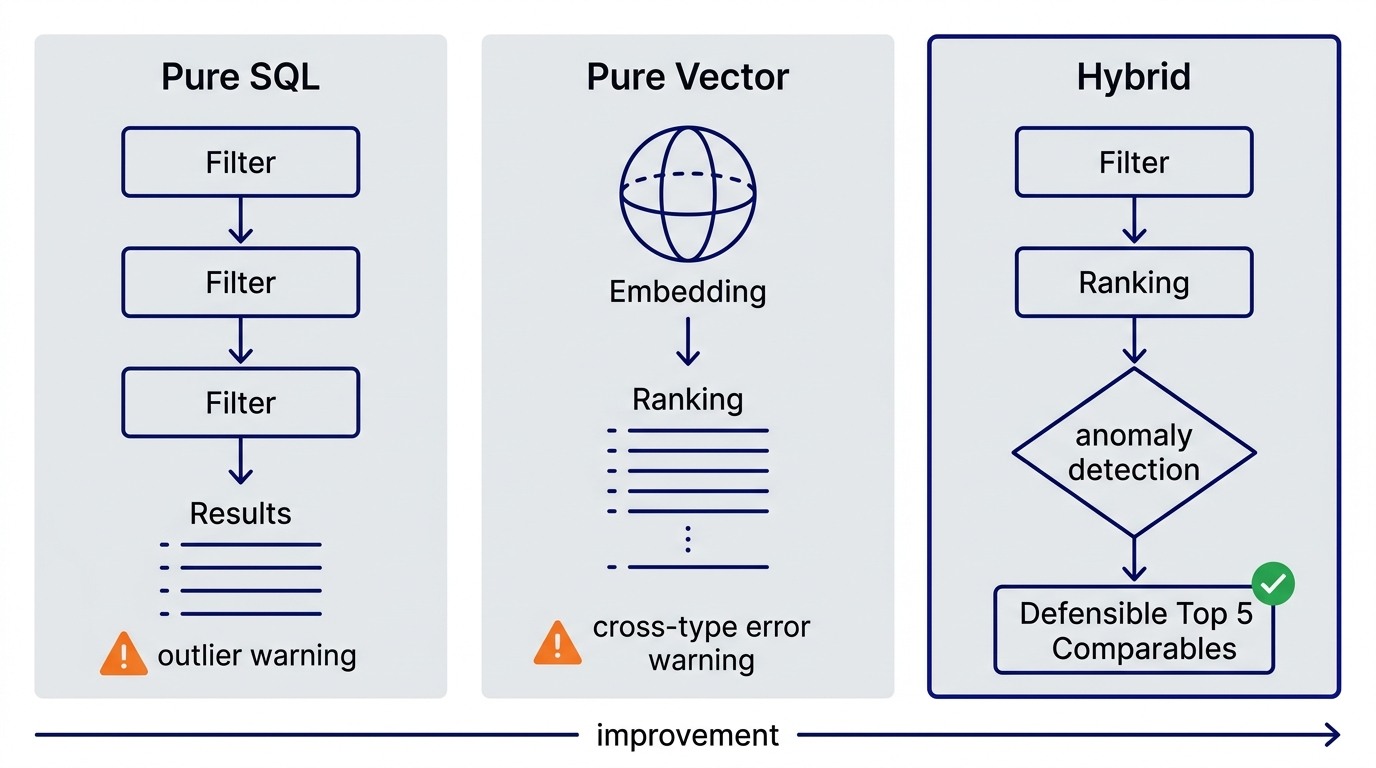
Here is the architecture that resolves both tensions.
Step 1: SQL Constraints
Run a SQL query to pre-filter. Select properties where:
- property_type matches your subject
- location is within the approved submarket (same postcode, or adjacent postcode if the regulator allows it)
- transaction_date is within the regulated window (typically 12 months for active markets, 24 months for slower markets)
- price is within a reasonable range
- land_area and built_up_area are within specified bands
This query is regulatory defensible. It returns 20 to 50 candidates.
Step 2: Vector Ranking
Now embed all 20 to 50 SQL candidates as vectors. Embed your subject property the same way. Compute semantic similarity. Rank the candidates by closeness to your subject in semantic space.
The vector algorithm now ranks within constrained choice. It is asking: "Of these LPPEH-compliant comparable properties, which one best represents my subject's market?"
The algorithm considers: recent price trajectory, condition and specification, tenant profile and occupancy, market segment features. All of this happens within the regulatory guardrails that SQL established.
Step 3: Anomaly Detection
The hybrid query can now do something pure SQL cannot: flag anomalies.
You know which comparables are regulatory compliant (SQL enforced that). You know which comparables are semantically close to your subject (vector ranked that). If a comparable is SQL-approved but vector-distant, it is an anomaly. It meets the rules but does not represent the market.
The system flags it. The valuer sees it. The valuer can include it with a manual adjustment, or exclude it with full documentation. Either way, the decision is documented and defensible.
Pure SQL would have returned the anomaly without flagging it. Pure vector would have rejected it based on semantics, not regulation. Hybrid catches both dimensions.
The MyScaleDB Case
MyScaleDB and similar hybrid-native databases are engineered specifically for this pattern. The database engine understands both SQL and vector natively. It can run hybrid queries efficiently.
The performance gain is significant. A naive implementation runs the SQL query, extracts candidates into application memory, embeds each candidate as a vector, computes similarity scores, joins results back to the database, and returns ranked results. This is slow and memory-intensive.
A hybrid-native database does this internally: run SQL query to select candidates, compute vector similarity within the database, join and rank in one query execution, return results.
MyScaleDB reports 10x speed improvement over the naive approach. More importantly, the compute cost collapses. Vector search on 20 candidates is cheap. Vector search on 1 million historical transactions is expensive. Hybrid pre-filters to 20, then searches within that set.
For a valuation software company, this matters operationally. If comparable selection takes 30 seconds per property, valuers will use it occasionally. If it takes 2 seconds, they will use it for every appraisal, making AI-assisted selection the default. Speed and cost efficiency enable adoption.
LPPEH Defensibility and Regulatory Audit
There is a reason the hybrid architecture matters for Malaysia specifically.
LPPEH has published guidance on comparable selection. The guidance emphasizes that comparables must meet hard criteria, must be adjusted for material differences, and comparable selection methodology must be explicit and defensible. An appraiser must be able to justify each comparable inclusion or exclusion.
A pure vector system cannot defend itself. It can show that a comparable "embeds near" the subject property. It cannot explain, in terms the regulator understands, why that comparable is chosen.
A hybrid system can explain itself. The SQL layer is completely transparent: "This comparable meets criteria X, Y, Z." The vector layer is interpretable: "Among all SQL-compliant comparables, this one is semantically closest because it has similar recent price growth, similar condition, similar market segment."
A valuer can defend this in front of the Board. An auditor can review this. It is transparent.
Malaysian valuers are increasingly required to document their AI-assisted methodologies. The Board wants to know: how did you select comparables? Why did you include this one and exclude that one? The hybrid architecture gives you an answer that regulators understand.
A Concrete Valuation Workflow
Let me walk through how this works for a commercial property valuation in Malaysia.
The valuer is appraising a 5,000 sqm shopping mall in Subang Jaya. Estimated value around RM 80 million. Occupied, mixed-use (retail and food court).
SQL Search (Regulatory Constraints)
- property_type = "shopping mall"
- location: Subang Jaya postcode + within 5km radius
- transaction_date: within 18 months
- built_up_area: 4,000 to 6,500 sqm
- price: RM 60m to RM 100m
- condition: good or excellent
Result: 18 comparable sales.
Vector Ranking (Market Intelligence)
Embed all 18 comparables and the subject property. Rank by semantic similarity. The ranking considers recent price trajectory, tenant anchor strength, occupancy condition, and renovation recency.
Result: Top 5 comparables, ranked 1 to 5 by market similarity.
Anomaly Flagging (Quality Assurance)
The system compares SQL-approved against vector-ranked. One comparable is SQL-approved but ranks 12th in vector similarity. The valuer sees: "This comparable is technically correct but is not representative of the current market. Do you want to include it with manual adjustment?"
The valuer decides to exclude it, with a note: "Comparable excluded because transaction occurred during market downturn and does not reflect current market conditions."
Appraisal Output
The valuer produces a report citing five comparable properties, ranked by market similarity, all meeting LPPEH regulatory criteria. The comparable selection methodology is transparent and defensible. The Board can audit it.
Compare this to pure approaches:
A pure SQL approach returns 18 comparables, uses the first five (arbitrary), includes the outlier because it is SQL-approved, does not capture market dynamics. Defensible but potentially inaccurate.
A pure vector approach embeds all comparables in the market, searches for semantic neighbors, gets back the shopping mall plus the residential apartment that embeds nearby. Technically inaccurate. Fails audit.
The hybrid approach constrains with SQL, ranks with vector, flags anomalies. Accurate and defensible. Passes audit. Represents market understanding.
The Governance Angle
For a PropTech company building valuation software in Malaysia, the hybrid architecture also enables better governance.
You can audit which comparables were selected and why. You can measure whether vector rankings are stable across multiple runs. You can track whether excluded anomalies correlate with market shifts.
This data becomes your quality feedback loop. You can publish a transparency report: "In Q1 2026, our system selected comparables for 500 appraisals. 94% of appraisals fell within 5% of final sale prices when measured six months after appraisal date. Anomaly exclusion improved accuracy by 3%."
That is the kind of defensibility that builds trust with valuers, regulators, and end clients.
For teams thinking about product architecture, this governance layer connects to The Self-Sustaining Handoff: the system should be auditable and explainable after you step back, not just while you are in it.
Precision and Intelligence Are Not in Tension
Step back to the macro picture. The tension was: AI valuation systems want to be both precise (follow regulations) and intelligent (understand markets). These seem to require different tools.
The hybrid architecture reveals that they are not in tension at all. They are two layers of the same question. Precision and intelligence are complementary, not contradictory.
SQL enforces what is knowable and rule-governed (regulations, property type definitions, location boundaries). Vector captures what is contextual and pattern-based (market dynamics, condition similarity, anomaly detection). Neither alone is sufficient. Together, they produce valuations that regulators can defend, valuers can explain, and clients can trust.
For a solo consultant building a valuation advisory model, for a PropTech startup building software for Malaysian valuers, or for an embedded executive modernizing a valuation practice, the hybrid architecture is not a technical optimization. It is the structure that aligns technology with professional judgment and regulatory requirement.
Precision without intelligence is defensible but blind. Intelligence without precision is insightful but indefensible. The property valuation systems that are scaling in regulated markets like Malaysia are those that combine both.
The choice is architectural: separate concerns (SQL for rules, vector for judgment), or collapse them into a single, opaque algorithm? In a regulated market, separate them. Make both transparent. Let the valuer see both layers and decide.
That is the architecture that makes AI valuations trustworthy.
Strategy and technology are the same decision. Over 15 years in fintech (CTOS, D&B), prop-tech (PropertyGuru DataSense), and digital startups, I have built frameworks that help founders and executives make both moves at once. Based in Kuala Lumpur.
Working on a 0→1 product?
I help founders and operators go from idea to validated product. Let's talk about yours.
Get in touch →