Background Queue Friday: The 30-Minute Monthly Reset

44 tasks. 30 minutes of active work. The highest throughput session in this workspace's history.
Those numbers are worth sitting with, because they represent a pattern that took several months to find by accident and a few more to understand well enough to systematize.
The pattern is this: tasks accumulate differently from how they get cleared. Individual tasks arrive one at a time, scattered across projects and contexts. Clearing them one by one, in the same reactive mode, produces marginal throughput. Clearing them in a single coordinated batch, in a fundamentally different mode, produces something qualitatively different.
The Problem with Reactive Task Management
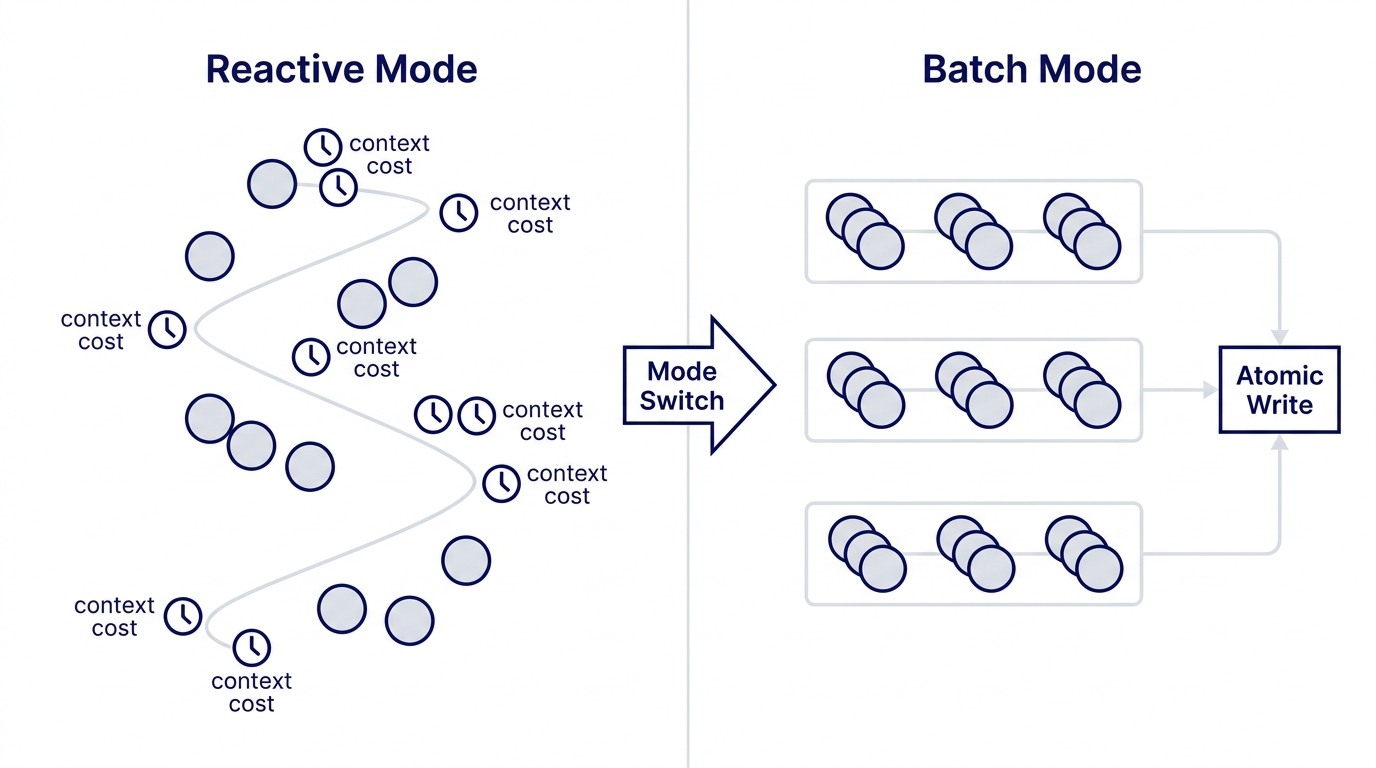
Most solo operators and embedded executives manage tasks the same way they manage email: one at a time, as they arrive, switching context between each one. A client follow-up leads to a research note, which leads to a draft, which gets interrupted by a scheduling conflict, which generates another task.
The result is a list that grows faster than it shrinks. Not because the work is not getting done, but because reactive clearance is structurally inefficient. Every task transition costs context-switching overhead. Every small task requires a mini orientation: what project is this for, what did I last know about it, what does "done" look like?
The alternative is not to work faster in reactive mode. It is to recognize that certain categories of work can be batched and dispatched in a completely different operational posture.
The named tension: accumulation vs. velocity. Tasks accumulate continuously. They clear most efficiently in concentrated bursts. The one-person company that only operates in reactive mode will always feel behind, not because it lacks capacity, but because it lacks the operational mode switch.
The Background Queue
I maintain a distinction between two types of tasks in my workspace.
Human-required tasks: strategic decisions, relationship actions, client review, approvals. These cannot be delegated. They need judgment in real time.
Claude-actionable tasks: research synthesis, document generation, skill builds, data processing, system configuration, writing. These require intelligence and time, but not real-time presence.
Over two weeks of ordinary work, the Claude-actionable queue grows. Not because it is being neglected, but because the human-required work is correctly being prioritized. By the first week of April, I had 88 tasks sitting in this queue across six projects.
That number sounds alarming. It is actually a sign the system is working: the work is being captured, the classification is accurate, and the human-required tasks are getting cleared while the automatable ones wait for their clearing moment.
The clearing moment is Background Queue Friday.
How the Session Works
The session runs once a month, targeting the first Friday morning. It takes 30 minutes of active engagement. The rest is orchestration.
The briefing does the setup. The night before, the daily briefing generator scans the task file, classifies all tasks by owner and status, and produces a "Claude Background Queue" section that groups the actionable tasks by project and independence. By morning, there is a pre-digested view of exactly what can be dispatched, clustered by which tasks can run in parallel without interfering with each other.
A single instruction triggers the session. After reading the briefing, one instruction goes in: "Let's be ambitious today. Clear all together." That is the only decision made at session start. The briefing has already done the analytical work.
Claude dispatches in parallel waves. Tasks are clustered into independent groups and dispatched simultaneously. In the April session, three waves of six to eight agents ran in parallel. Each agent received explicit scope: project name, specific tasks, output constraints, and a directive to not create supplementary documentation unless requested. Each agent wrote to its own designated output path. No two agents touched the same file.
Completion is atomic. After all waves complete, a single Python script reads the task list, matches completed work against task descriptions, and rewrites the task file in one operation. No incremental edits, no sequential toggles. One read, one process, one write.
The Numbers
Forty-four tasks completed in 30 minutes of active engagement time. 1.3 tasks per minute of active work.
To put that in context: at normal reactive throughput, completing 44 tasks with appropriate quality would require four to six hours of focused work across multiple days. Context switching, re-orientation, and single-threading would consume the rest.
The token cost was substantial, approximately 1.83 million tokens across three agent waves. But that is the right unit of exchange. Senior professional time at embedded executive rates is worth protecting. Claude usage is renewable weekly. The trade is asymmetric in the right direction.
The creative-to-plumbing ratio was 65% creative (new skills, articles, evaluation reports, architecture documents) to 35% plumbing (schema updates, patches, manifest entries). For a queue-clearance session, this is healthy. Most of the plumbing was genuinely necessary infrastructure that had been accumulating.
What Makes It Work
Three components produced this result, and all three are necessary.
The briefing as session brief. The daily briefing eliminates the "what should I work on?" negotiation entirely. When I arrive at the session, there is no triage needed, no evaluation, no sequencing. The session opens with execution, not planning.
This took months to build correctly. The briefing now produces a section called "Claude Background Queue" that lists only the automatable tasks, sorted by project, grouped by independence cluster. That section is the session brief. Without it, the 30-minute session would take 90 minutes.
The trust model. The session required giving a single blanket instruction rather than approving each batch. For background queue work (skills, documentation, scripts, articles that will go through a review pass before deployment) this trust level is correct. The high-stakes outputs (security documents, financial data, governance frameworks) get spot-checked before being treated as production-ready. Everything else ships.
The trust model is not "dispatch and forget." It is "dispatch, then spot-check the things that matter, treat the rest as done." Requiring approval at each batch would have quadrupled active engagement time and eliminated most of the throughput gain.
The isolation guarantee. Each agent wrote to its own path. No shared files. No sequential dependencies within a wave. The consolidation step happened once, after all agents completed, via a single atomic write. This prevented the drift and partial-state errors that happen when multiple processes touch the same resource.
The failure mode encountered: one agent created a copy of a skill folder rather than editing the existing folder in place. The instruction said "update a skill" and the agent interpreted that as "create a new version." Future dispatch prompts now include an explicit directive: "Edit the existing file in place. Do not create a new folder." One line. Prevents the problem entirely.
The Platform Ecosystem Thesis in Practice
There is a deeper pattern worth naming.
The briefing-to-dispatch pipeline is composed of three components built in separate sessions over three weeks: the facilitator that classifies and clusters tasks, the briefing generator that produces the morning brief, and the dispatch pattern refined in the clearance session itself.
Individually, each is useful. Composed, they produced 44 completions in 30 minutes.
This is the platform ecosystem thesis applied to personal productivity: interdependent nodes create compounding value through integration, not feature competition. The briefing is not valuable because it is a good summary document. It is valuable because it is the input format that the dispatch session was designed to consume.
This is exactly the compounding logic in The Self-Sustaining Handoff. The output of one layer becomes the designed input of the next. The value is in the interface, not just the component.
Most productivity tools are designed to be used in isolation. The one-person company that builds interconnected systems, where the output of one component is the designed input of the next, gets to operate at a qualitatively different level.
How to Replicate This
The pattern is not tool-specific. The structure is transferable.
Build the classification layer first. You need a way to distinguish work that requires your presence from work that does not. If your task list does not make this distinction, start there. Tag tasks by owner (human vs. automatable) and by independence (can this run without depending on an in-progress task?).
Build the briefing layer second. Before your clearance session, you need a pre-digested view of what is in the automatable queue, clustered by independence. This does not need to be automated. A 10-minute manual review of your task list the night before, with tasks grouped into independent clusters, achieves the same function.
Set a cadence and protect it. The first Friday of the month works because it follows naturally from the accumulation cycle. Tasks accumulate over two to four weeks. The clearance session catches them before the queue becomes unmanageable. Make the date predictable so the system's behavior becomes predictable.
Spot-check before deploying. Not everything that comes out of a batch session is production-ready. Flag your highest-stakes outputs at dispatch time. Set 15 to 20 minutes aside after the session for review. Do not conflate "the agent produced it" with "it is ready to use."
The connection to Brief-then-Fire is direct: the batch session is the operationalized version of that principle. The briefing is the brief. The dispatch is the fire. The spot-check is the gate.
A Note on Volume
88 tasks sounds like a lot. It is, by reactive-mode standards. By batch-clearance standards, it is exactly right.
The queue should accumulate until a clearance session is warranted. If the queue empties after two days, the clearance session has no advantage over reactive mode. If it grows for six weeks, the backlog becomes disorienting and the session itself takes longer to triage.
Two to four weeks of accumulation, followed by a 30-minute clearance, is the right cadence for a solo operator running three to six parallel projects. Adjust for your own accumulation rate.
The goal is not to have zero tasks. The goal is to have zero tasks that are blocking you when they could be running in the background.
Strategy and technology are the same decision. Over 15 years in fintech (CTOS, D&B), prop-tech (PropertyGuru DataSense), and digital startups, I have built frameworks that help founders and executives make both moves at once. Based in Kuala Lumpur.
Working on a 0→1 product?
I help founders and operators go from idea to validated product. Let's talk about yours.
Get in touch →