Five Models, Five Jobs: A Framework for Choosing the Right AI

The AI world has a capability obsession. Which model scores highest on academic benchmarks? Which has the largest context window? Which is most "advanced"?
A working professional does not face a capability question. A working professional faces a selection question: which model should I use for this task, right now, given my constraints?
Those are different problems entirely.
I have spent six months auditing my own AI usage across valuation, management accounting, and operational advisory. I run roughly 400 AI queries per month. Some are complex. Most are routine. Some involve images. Most involve text.
When I started paying attention to model selection (not model capability, but selection), I discovered I was systematically over-specifying. I was using the most capable models for routine tasks. I was paying GPT-4o prices for work that Claude Haiku could handle. I was using text models for visual problems.
The result: I was wasting 40 to 55% of my AI budget.
A simple framework changed this. Not a framework about which model is best (a meaningless question), but a framework about job fit.
The Five-Model Taxonomy
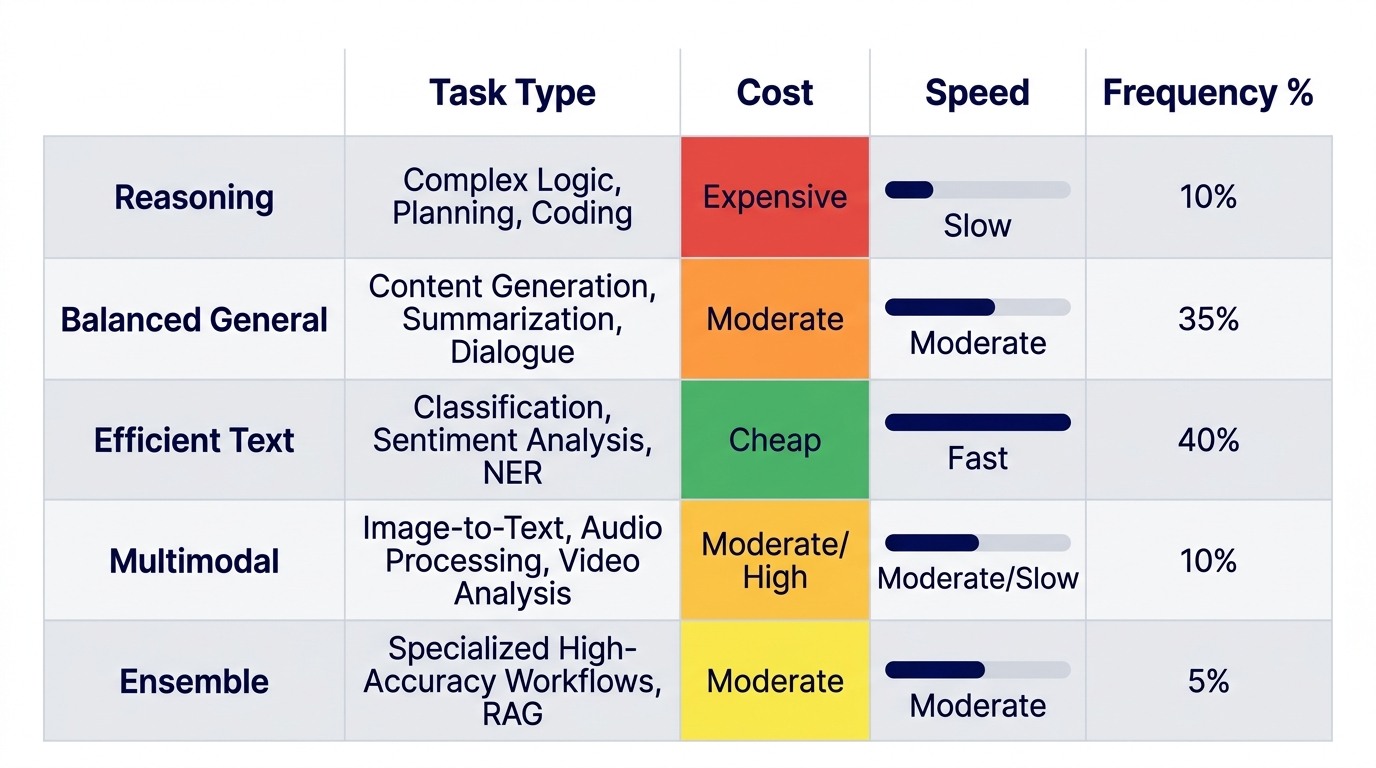
I organize AI models into five categories. Not by capability. By job type. Each job type has different economic and technical requirements.
1. Reasoning Models: o3, o1, o1-preview
These are expensive. They are slow. They trade cost and speed for depth of analysis.
Use them when the problem requires multi-step reasoning and the cost of a wrong answer is high:
- Complex valuation adjustment decisions where the reasoning will be litigated
- Portfolio stress testing with regulatory implications
- Interpretation of ambiguous regulatory text where the wrong reading carries exposure
- Long-form strategic analysis where the reasoning must be airtight
- Complex cost allocation decisions in management accounting where the methodology will be audited
Cost model. High. These models can cost 10 to 40x more per query than efficient models. If the alternative is a decision error with six-figure exposure, the economics are justified.
Speed. Slow. o3 can take 30 to 60 seconds for complex queries. If you need instant response, do not use these models.
Frequency in professional practice. 5 to 10% of queries. Most professionals dramatically overuse reasoning models because they associate cost with quality. The opposite is true. Expensive models are specific tools for specific problems.
2. Balanced General Models: GPT-4o, Claude Sonnet, Gemini 2.0 Flash
The workhorse. Fast. Moderate cost. Good quality across a wide range of tasks.
Use them for routine professional work where quality matters but the task does not require deep reasoning:
- Drafting valuation reports (first pass)
- Summarizing market data and trends
- Writing client communications and emails
- Creating meeting notes and summaries
- Initial analysis of comparable properties
- Advisory memo composition
Cost model. Moderate. Typically $0.005 to $0.02 per thousand tokens.
Speed. Fast. Typically 2 to 5 seconds for standard queries.
Frequency in professional practice. 70 to 80% of queries. This is where your AI budget should concentrate.
The strategic insight: most professionals are over-specifying here. They assume that professional work needs the smartest model. Professional work needs fast, consistent, capable-enough models. Balanced models are built for this job.
3. Efficient Text Models: GPT-4.1, Claude Haiku, Gemini 1.5 Flash
Fast and cheap. They sacrifice some nuance for speed and cost.
Use them for high-volume, repetitive tasks where consistency matters more than precision:
- Extracting structured data from property descriptions (batch across 50 properties)
- Running the same comparable analysis across a portfolio
- Classifying documents into categories
- Summarizing many short documents (100+ in a single operation)
- Routine data cleaning and transformation
Cost model. Low. These models cost 80 to 90% less than balanced general models.
Speed. Very fast. Often 1 to 2 seconds for standard queries.
Frequency in professional practice. 10 to 15% of queries. Dramatically underused by professionals who default to general models.
The strategic insight: professionals hesitate to use cheap models because they associate low cost with low quality. In fact, cheap models are built for volume. If your task has volume, use them.
4. Multimodal Models: GPT-4o Vision, Gemini Pro, Claude Vision
These handle images, diagrams, PDFs, and mixed content.
Use them whenever your primary input is visual or the analysis requires visual interpretation:
- Property condition assessment from building photographs
- Flood risk mapping from aerial satellite imagery
- Architectural document analysis and space planning
- Extracting data from scanned or photographed documents
- Interpreting floor plans and spatial diagrams
Cost model. Moderate to high.
Speed. Moderate. 3 to 10 seconds depending on image size and complexity.
Frequency in professional practice. 5 to 10% of queries for professionals in property, engineering, or environmental domains.
The strategic insight: professionals with visual workflows often try to convert images to text and use text models. Wrong approach. Use multimodal models. The native approach is faster and more accurate.
5. Ensemble/Council Models: Multiple Models in Parallel
Not a single model, but a fleet. Run the same query through two or three models and compare outputs.
Use them for high-stakes decisions where defensibility matters more than speed:
- Comparable property selection for litigation or regulatory valuations
- Portfolio allocation decisions with audit requirement
- Regulatory interpretation where the decision will be challenged
- Complex cost allocation in regulated industries
Cost model. High. Running three models triples the cost for that query. The insurance value is significant if the decision carries high exposure.
Speed. Slow if run in series. Only slightly slower than a single model if run in parallel.
Frequency in professional practice. 1 to 5% of queries. Only for high-stakes work.
The Economics of Model Selection
Here is the formula I use to decide which model to apply:
Total cost per task = (unit cost of model) × (expected query volume) × (task fit multiplier)
The task fit multiplier is what most professionals ignore. A capable model that is not fit for the job produces low quality and requires rework. The rework costs more than using the right model in the first place.
Three concrete examples:
Example 1: Drafting a 2,000-word valuation report.
- Option A: o3 (reasoning model). Cost: $20 per draft. Time: 90 seconds. Excellent quality.
- Option B: GPT-4o (general model). Cost: $0.08 per draft. Time: 8 seconds. Very good quality.
- Option C: Claude Haiku (efficient model). Cost: $0.02 per draft. Time: 5 seconds. Adequate quality, needs minor revision.
For a one-off report, option B is optimal. Option A is over-specified. Option C is under-specified (rework required).
Example 2: Extracting property attributes from 500 listing descriptions.
- Option A: GPT-4o. Cost: $2.50 for all 500. Quality: 98%.
- Option B: Claude Haiku. Cost: $0.35 for all 500. Quality: 92%.
If the extracted data goes to a human analyst who validates, option B is optimal. If it feeds directly to an algorithm, option A is safer.
Example 3: Regulatory interpretation of a complex guidance document.
- Option A: GPT-4o. Cost: $0.40. Risk: interpretation might miss nuance.
- Option B: o3. Cost: $15. Risk: very low, reasoning is deep.
- Option C: Ensemble of both. Cost: $15.40. Risk: lowest, decision is traceable.
For a one-off high-stakes interpretation, option B. For a decision that will be audited or litigated, option C. For a preliminary reading, option A.
The pattern: match the cost and capability of the model to the stakes and volume of the task. Over-specification wastes money. Under-specification wastes time through rework or creates risk through error.
Operationalizing the Framework
I have organized my own AI usage around a simple decision tree:
- What is the task? (reasoning, routine, repetitive, visual, ensemble)
- What are the stakes? (none, moderate, high, critical)
- What is the volume? (one-off, handful per month, batch, hundreds per month)
- What is the error cost? (ignorable, tolerable with review, expensive, catastrophic)
Map your task to the five categories. Select the model that fits the category. Run a test query. Evaluate quality. Adjust if needed.
Do this for a month. Track which models you use, which tasks, what quality, what cost. Most professionals discover they are over-specifying on 30 to 40% of their queries. Correcting this reduces costs by 40 to 60% without quality loss.
The second-order benefit: once you understand your task distribution, you can design your workflow around it. Batch your repetitive tasks into efficient model runs. Schedule your reasoning tasks into reasoning model queries. Pipeline your visual analysis into multimodal models.
This connects to what I call the Token Economy as Cash Economy principle: token spend is not a uniform line item. It is a portfolio of different-cost, different-yield investments. Manage it accordingly.
From Capability Obsession to Job Fit
The AI industry spends enormous energy arguing which model is "best." The conversation is entirely about capability: benchmark scores, context window sizes, reasoning depth, knowledge cutoff dates.
The working professional does not care about capability rankings. The working professional cares about job fit and total cost of ownership.
The best model is not the one with the highest benchmark score. The best model is the one that solves your specific problem at a cost you can afford.
This reframing changes how you evaluate models. It also changes how you budget for AI. Most organizations treating AI as a cost center calculate total spending and try to optimize globally. Wrong approach.
Better approach: calculate cost per task type. Understand your task distribution. Optimize model selection within each type. Total spending optimizes as a side effect.
This is management accounting applied to AI operations. It is cost driver analysis. Not glamorous. But it delivers 40 to 55% cost reduction without quality loss, and every working professional can do it immediately.
The spreadsheet is straightforward:
| Task Type | Model | Cost | Quality | Volume/Month | Total Cost |
|---|---|---|---|---|---|
| Complex valuation adjustment | o3 | $20 | Excellent | 3 | $60 |
| Client reporting | GPT-4o | $0.08 | Very good | 30 | $2.40 |
| Data extraction | Claude Haiku | $0.02 | Adequate | 200 | $4.00 |
| Property assessment from photos | GPT-4o Vision | $0.15 | Excellent | 20 | $3.00 |
| High-stakes regulatory decision | Ensemble | $15 | Excellent | 1 | $15 |
Total: $84.40 per month for approximately 254 professional queries.
A single-model strategy (using GPT-4o for everything) would cost roughly $35 to $40 per month in API costs. But the rework and revision costs for inappropriate model choices would be 3 to 4x higher.
The five-model framework costs slightly more in API fees but delivers better quality, faster execution, and significantly lower total cost of ownership.
That is the practical insight: model selection is not about finding the best model. It is about designing a toolkit that matches your actual work.
For how this fits into a broader AI workflow built around The 95% Margin Workflow, the principle is the same: the goal is not maximum output, it is maximum output per dollar of input, achieved through deliberate allocation rather than brute force.
Strategy and technology are the same decision. Over 15 years in fintech (CTOS, D&B), prop-tech (PropertyGuru DataSense), and digital startups, I have built frameworks that help founders and executives make both moves at once. Based in Kuala Lumpur.
Working on a 0→1 product?
I help founders and operators go from idea to validated product. Let's talk about yours.
Get in touch →