LLM Councils: Why Ensemble AI Makes Professionals More Defensible

You run a comparable selection through an LLM. The output looks professional. It selects four comparables with coherent reasoning. You review it, maybe tweak one element, and it becomes part of a valuation that gets signed and filed.
But here is what you did not see: you did not see the comparables the model considered and rejected. You did not see whether the model's selection reflected genuine market confidence or statistical averaging. You did not see whether the model was certain or guessing.
This is the hidden cost of a single AI output in regulated professional work. The model makes a judgment. You inherit the judgment without seeing the reasoning underneath.
Now imagine running that same task through three independent models. GPT-4o, Claude Sonnet, Gemini Pro. Same brief, three simultaneous outputs, no communication between them.
What you get is not three competing judgments. What you get is a diagnostic tool. The models will converge on obvious choices. They will diverge on ambiguous ones. That divergence is the signal. It is where your professional judgment is most needed.
This is the principle of an LLM council: not a single oracle, but an ensemble where disagreement is the deliverable.
How Councils Work in Practice
Let us be concrete. A valuation requires comparable property selection. The valuer has narrowed the universe to twelve candidate properties. The question: which four represent the truest market data for this subject?
Run the brief through a single LLM. The model will select four comparables with explanation. The output looks defensible. The reasoning sounds like an experienced valuer's reasoning.
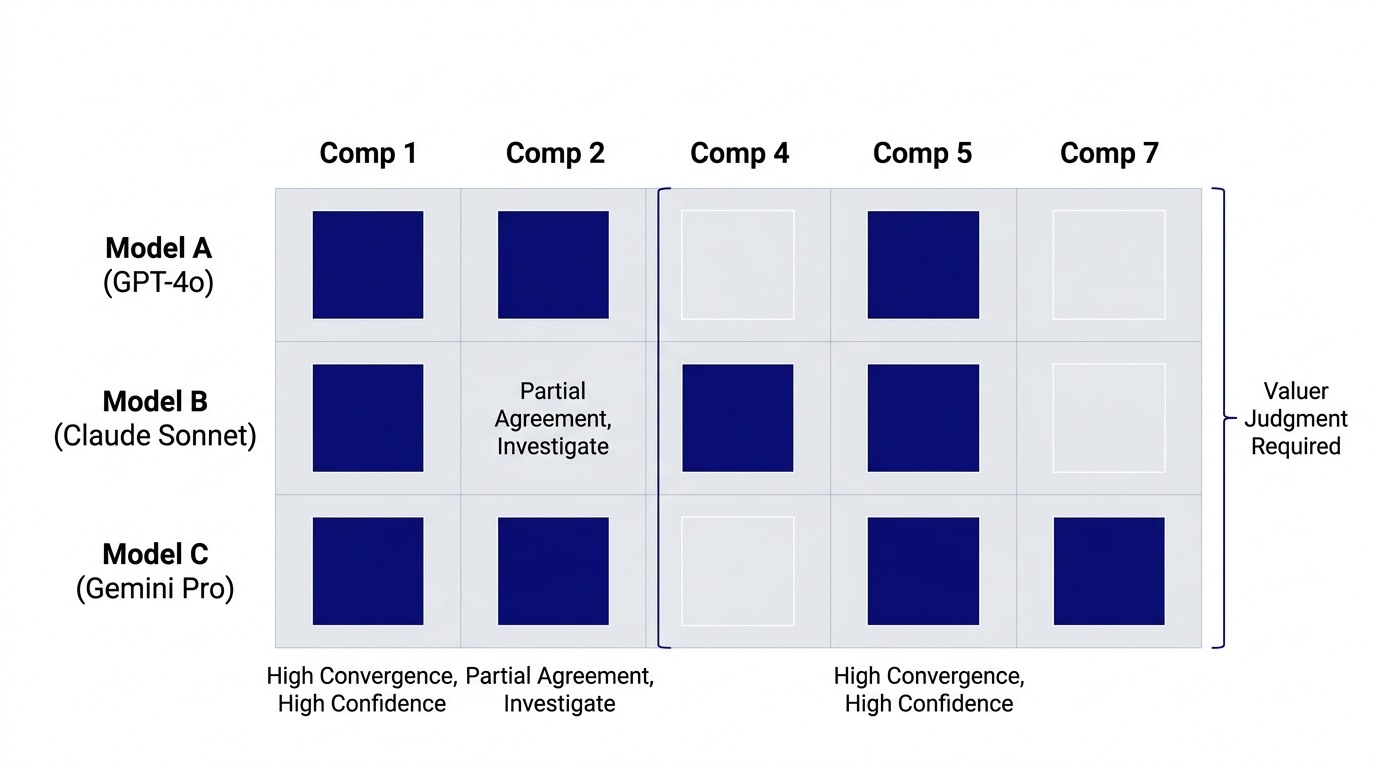
Now run the same brief through three models in parallel. Model A selects comparables 1, 2, 3, 5. Model B selects 1, 3, 4, 5. Model C selects 1, 2, 5, 7.
You now have data. All three selected comparable 1. High convergence. All three selected 5. High convergence. Model A and C chose comparable 2, but B did not. Divergence. Model B chose 4, but A and C did not. Divergence. Model C chose 7, but A and B did not. Divergence.
The convergence zone (1 and 5) is high confidence. The divergence zone (2, 4, 7) is ambiguous in the market data. The ambiguity might reflect genuine uncertainty in recent transactions, or it might reflect how the models were trained on historical data, or it might reflect actual differences in how the three models weight recency versus statistical reliability.
That ambiguity is your cue. As the registered valuer, this is where you earn your qualification. You investigate the divergence. You check: are comparables 4 and 7 recent transactions with lower credibility? Is comparable 2 in a micromarket with inconsistent pricing? Your human market knowledge determines whether the divergence reflects real market uncertainty or model noise.
The council's output is not the comparable set. The council's output is a map of where the models agree and where they disagree. You make the final judgment call, but you make it from a position of visibility.
The Regulatory Dimension
LPPEH and IVSC standards require human judgment. They do not permit valuation by algorithm. An LLM council satisfies this requirement in a way a single model cannot.
A single model's output invites a question: how would we know if the model was wrong? The model's reasoning sounded coherent. The comparable set sounded reasonable. But without seeing alternatives, the reviewer has limited grounds to challenge the judgment.
An LLM council's output is systematically comparable to human judgment. The disagreement between models creates a decision trace. A regulator or a litigator can ask: "Why did you choose comparable 2 when model B flagged it as divergent from the consensus?" You can answer with evidence: "Two models selected it. One did not. I reviewed the market data for comparable 2 and found [reason]. The market supported its inclusion."
That is auditable. A single model's output is not.
The Cost Structure
Running three LLM API calls instead of one triples the marginal cost for that task. On a property with a modest valuation fee, running a council might add $50 to $150 to direct costs.
Measure that against the downside. A valuation challenge in litigation or regulatory review exposes the firm to significant legal and reputational cost. The council's cost is trivial insurance against that exposure.
More subtly, the council reduces the risk of reputational contagion. If a single valuation is challenged, the question emerges: might other valuations from this firm have the same methodological gap? An LLM council creates a visible distinction between valuations done with ensemble methodology and those without. Over time, the council becomes a market differentiator.
This is the same logic behind the prompt chain investment described in Token Economy as Cash Economy: the additional spend per run is not overhead. It is the cost of building a defensible professional position.
The Operational Intelligence Layer
Most councils are one-off defensibility plays. Run the models, make the decision, move on. But if you keep records of the ensemble outputs, they become a data asset.
Over time, you can see which model tends to be more conservative in comparable selection. You can see which comparable types are most often disputed (recent renovations? mixed-use properties? properties in transition markets?). You can see which case types produce persistent divergence between models.
That pattern data becomes a filter for your own judgment. If model divergence on renovation premium is routine across fifty cases, you know to investigate renovation premiums more carefully in your next valuation. If one model consistently selects more recent transactions while another favors statistical stability, you can weight the models differently based on your market assessment.
The council evolves from a defensibility mechanism into a professional intelligence system.
Extension to Other Regulated Domains
Property valuation is the obvious case, but councils apply wherever regulated judgment and AI intersect.
Environmental risk assessment: run flood risk modeling through three hydrological models in parallel. Consensus zones are high confidence. Divergence zones require field verification or additional data collection.
Cost accounting: run allocation of indirect costs through three different cost driver models. Consensus allocations are reliable. Divergence in specific cost pools signals that the driver selection is ambiguous and warrants sensitivity analysis.
Regulatory interpretation: run the same regulatory brief through three models. If they converge on interpretation, confidence is high. If they diverge, the regulatory text is ambiguous and legal review is warranted before proceeding.
In every domain where regulation requires human judgment and AI is being introduced, the council pattern applies. The Self-Sustaining Handoff depends on this kind of structured output: when the decision trail is visible, the handoff is clean and defensible.
From Oracle to Diagnostic
The professional conversation about AI tends to focus on capability: which model is smarter, which produces fewer hallucinations, which scores highest on benchmark tests. Those questions matter, but they miss the real tension in regulated practice.
Regulated professionals want AI assistance. But they need to maintain defensibility. A single AI output creates a single point of failure. If the model was wrong, you were wrong. If the model hallucinated, you inherited the hallucination.
An ensemble where models disagree inverts this tension. Disagreement becomes an asset, not a liability. The disagreement makes visible exactly where human judgment adds value. The judgment call becomes auditable. The decision process becomes comparable to how a human professional would reason through the same problem.
The council is not about replacing your judgment. It is about showing you exactly where your judgment is most needed.
A single AI model is an oracle. You ask a question, the oracle speaks, you act. The oracle has no accountability and no transparency.
An ensemble of AI models that disagree with each other is a decision support system. You ask a question, the models speak in parallel, they agree on some things and disagree on others, and you make the judgment call based on visible evidence.
This is the professional version of AI augmentation. Not AI replacing judgment, but AI making judgment visible, auditable, and defensible.
The regulatory environment will evolve toward this. Not because regulators distrust AI, but because they require visible judgment trails and defensible decision processes. The LLM council provides both.
For practitioners willing to invest in the methodology, councils become a market advantage. Not just in regulation and litigation (where they provide defensibility), but in competitive positioning (where they signal professional rigor to clients who are increasingly sophisticated about AI risk).
The oracle era of AI in professional work is ending. The council era is beginning.
Strategy and technology are the same decision. Over 15 years in fintech (CTOS, D&B), prop-tech (PropertyGuru DataSense), and digital startups, I have built frameworks that help founders and executives make both moves at once. Based in Kuala Lumpur.
Working on a 0→1 product?
I help founders and operators go from idea to validated product. Let's talk about yours.
Get in touch →