Reverse-Engineering Malaysian Government Portals: A Reusable Crawl Pattern

A session crawling Malaysia's licensed valuation negotiator registry surfaced a reusable pattern for any Malaysian government public portal. Three traps, three escape routes, one starter template.
The Premise
Malaysian government portals expose data the public is technically allowed to read but practically locked away behind painful interfaces. Licensed valuers, registered negotiators, property transactions, vehicle registrations, professional registries: all reachable through a browser, none of them exposing a clean API.
The pragmatic move is to build a crawler. The trap is that each new portal looks different on the surface. The pattern below shows that most of them are the same underneath, and the cost of figuring that out should be paid once.
Named tension: every new portal looks bespoke. Most of them are the same five frameworks wearing different paint. Treating each one as bespoke is the tax. Recognising the pattern is the lever.
The Trigger Case
The Board of Valuers, Appraisers, Estate Agents and Property Managers (LPPEH) operates a public registry of licensed real estate negotiators in Malaysia. Roughly twenty thousand records. Public. Searchable. Slow.
The site front-end at lpeph.gov.my is a plain HTML brochure. The data lives at bis.lpeph.gov.my. The two are connected by an iframe that the average crawler does not see.
The naive approach: point a scraper at lpeph.gov.my, follow links, parse HTML. This produces zero useful records. The data is not on the page the scraper is looking at.
The right approach: probe deeper. Find the iframe. Inspect the iframe's source. Discover that the search lives behind a JavaScript framework with very specific behaviour. Build the crawler against the actual data plane, not the marketing wrapper.
That probe-first discipline is the pattern.
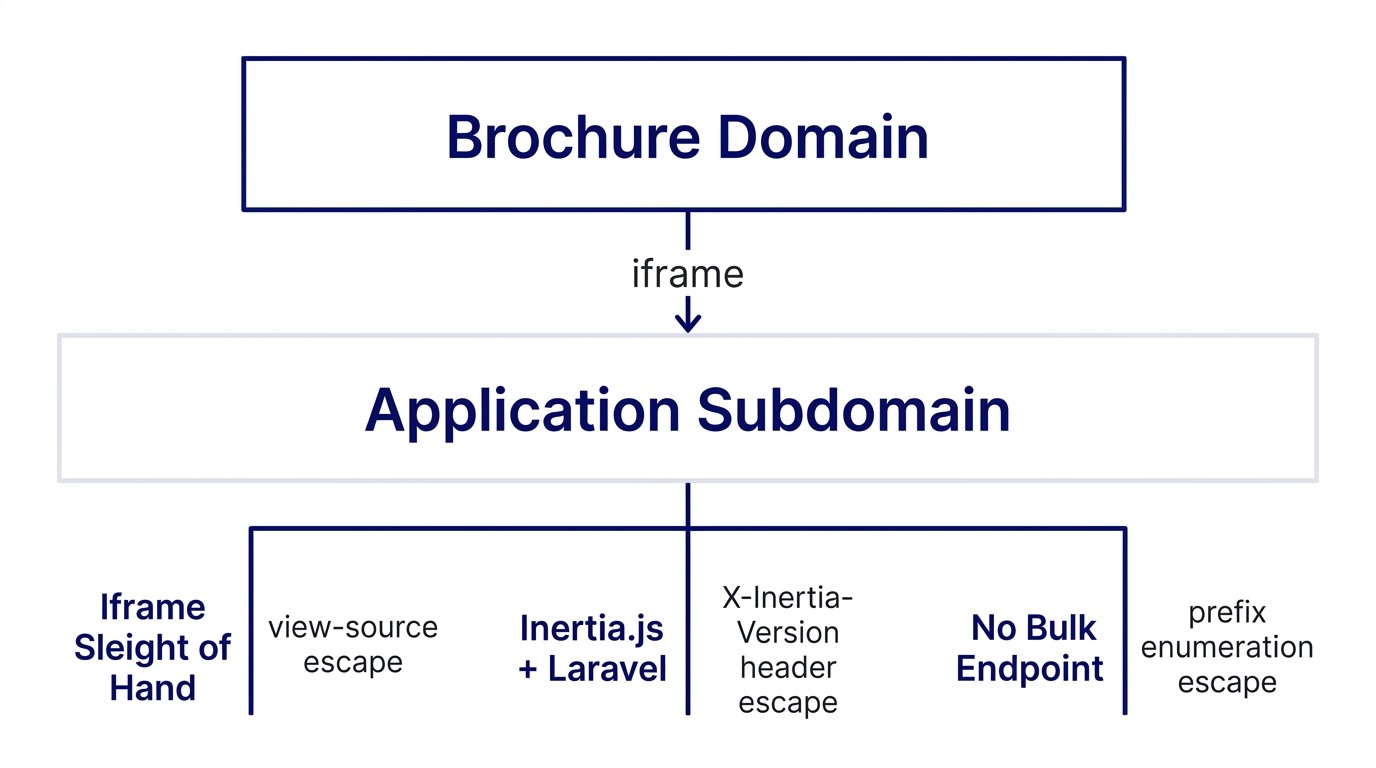
Three Traps Worth Naming
Trap 1: The Iframe Sleight of Hand
A surprising number of Malaysian government portals expose their actual application as an iframe inside a static brochure site. The brochure exists for branding, accessibility statements, and a "go back to the ministry" link. The application is hosted on a subdomain that the brochure embeds.
If you crawl the brochure, you get the brochure. The data is one frame deep, on a different host, often with different auth, different rate limits, and different framework behaviour.
Escape: before writing a single line of crawler code, view the page source. Search for iframe. If one exists, the rest of your crawler should target the iframe's src host, not the parent domain. Treat the parent as decoration.
Trap 2: The Inertia.js + Laravel Stack
Half of Malaysian government portals built since 2022 use Laravel on the backend with Inertia.js as the frontend bridge. Inertia is a thin layer that lets a Laravel application return either a full HTML page (for the first request) or a JSON payload (for subsequent navigations) from the same routes.
This sounds neutral until you try to crawl one. The first request returns a full HTML page wrapped around a JSON blob in a single <div id="app" data-page="..."> element. Subsequent requests, made the way the JavaScript app makes them, return pure JSON via a special X-Inertia header and a X-Inertia-Version token.
If you make the second request without the right headers, you get a 409 Conflict and a redirect HTML page. If you make it with the wrong version token, you get a 409 Conflict and a redirect HTML page. The error is the same in both cases. The fix is different.
Escape: extract the X-Inertia-Version token from the first HTML response (it lives in the same data-page blob). Pass it on every subsequent request along with X-Inertia: true. Treat the page-level routes as JSON endpoints once you have the version. The crawler reads JSON, not HTML, after the first request.
Trap 3: The "All Records" Endpoint That Does Not Exist
Pre-2020, most government portals had an "all records" or "browse all" endpoint somewhere. Post-2020, that pattern is largely dead. The current pattern is a search interface that requires a query, and the query field has a minimum-length validation.
There is no /api/all-negotiators or /api/dump endpoint. The site is designed to be browsed by a human searching for a specific name. The data set is technically public, but the interface assumes one query at a time.
Escape: enumerate via the smallest valid prefix. For LPPEH, the registration number always starts with REN, then digits. The crawler queries 0, 1, 2, through 9 as REN-number prefixes. Each query returns up to a few thousand matches. Combined, they return the full set with a small overlap. Deduplicate on the internal record ID.
This is uglier than a clean dump endpoint. It is the path that exists, and the framework above (Inertia + Laravel) makes the queries cheap once you know how to call them. Two workers, half-second delay between requests, completes a full registry crawl in about an hour.
The Reusable Template That Came Out of It
After three sessions on three different Malaysian government portals, I extracted the common scaffold into a single starter file: templates/my-gov-portal-public.py.
It contains:
-
Three-parallel-probes function: hits
/,/api,/adminsimultaneously and reports response codes plus framework fingerprints (cookies namedXSRF-TOKENindicate Laravel;data-pagediv indicates Inertia;data-controllerindicates Stimulus). -
Iframe pre-probe: checks the parent page for iframes before any crawling logic runs. If found, automatically retargets the host of the first iframe and prints a warning.
-
Inertia-aware fetch helper: extracts version token from first response, persists it across requests, sets the right headers on every subsequent call.
-
Auth-model check: tries an unauthenticated request to a likely-protected endpoint. If it returns 200 with data, the portal is fully public. If it returns 401, the portal is auth-walled and the crawl needs a session token. If it returns 200 with a sign-in page, the portal is using soft-auth and most data is reachable without login.
The template costs about two hours to clone, fill in, and produce a working crawler against a new Malaysian portal. Without the template, the same crawler costs eight to twelve hours of trial and error.
Practical lever: the second crawler in a class is always cheaper than the first. The third one is dramatically cheaper than the first if you wrote the template after the second one.
The Wider Lesson
The framework cost of the LPPEH crawler was nothing. Inertia.js is documented. Laravel is documented. The probe technique is standard.
The cost was assumption replacement. The first hour was spent assuming the portal was a vanilla server-side-rendered HTML site. It is not. The second hour was spent assuming the data lived at the marketing domain. It does not. The third hour was the actual crawling work, which was almost mechanical once the framework was named correctly.
If I had walked into the session with the three-probe protocol from minute one, the assumption replacement would have happened in five minutes instead of two hours. The crawler itself would have been the same.
This is the case for tooling that captures patterns rather than scripts that capture solutions. A script for "crawl LPPEH" is worth one crawler. A template for "crawl any Inertia + Laravel Malaysian government portal" is worth ten, with a marginal cost approaching zero.
The same principle applies in The Self-Sustaining Handoff: the artefact you build should teach the next person or agent to run it without you. A template does this. A one-off script does not.
What I Would Do Next
Three things, in order of value.
-
Extend the template with a Vue + Vite branch. A growing fraction of Malaysian portals are migrating away from Inertia to a separated Vue app calling a JSON API. The framework fingerprint check should branch into "Inertia" or "Vue + REST" and offer the right helpers for each.
-
Capture the auth model patterns. Malaysian portals use one of four common auth models: no auth, soft-auth (username only), hard-auth (username plus OTP), or login-then-session. Each has a known interaction pattern. The template should detect which one the portal uses and offer the right handler.
-
Build a crawl orchestrator. Once you have three or four portal crawlers, the next bottleneck is scheduling, dedup across runs, and merging output into a single dataset. A small orchestrator (cron plus a Postgres table) handles this for any Malaysian government portal crawl with minor adapters.
None of this is glamorous. All of it pays compounding dividends across every future Malaysian data pipeline.
The Reusable Skill
The pattern itself is now a skill in my browser harness called inertia-js. It documents the two-step fetch, the 409 trap, the Ziggy route extraction, and the full header reference. The first agent that hits an Inertia + Laravel portal in a future session reads the skill and skips the two hours of discovery I paid this week.
This is the right shape for accumulated knowledge in an AI-assisted operation: the human (or agent) discovers the pattern once, captures it as a skill or template, and the next encounter is fast. The cost of pattern recognition is paid by the first practitioner. The benefit accrues to every practitioner after.
For agencies and consultancies operating in Malaysian public-data work, the practical move is: keep a private library of these patterns. Add to it after every crawl session. Treat the library as the IP, not the individual scripts. The scripts depreciate. The library compounds.
This is the same logic I apply to AI workflow architecture: the durable asset is the process knowledge, not any single output.
Written from a session crawling LPPEH's negotiator registry. The crawler is in production. The pattern is in the template folder. The next portal will take two hours instead of eight.
Strategy and technology are the same decision. Over 15 years in fintech (CTOS, D&B), prop-tech (PropertyGuru DataSense), and digital startups, I have built frameworks that help founders and executives make both moves at once. Based in Kuala Lumpur.
Working on a 0→1 product?
I help founders and operators go from idea to validated product. Let's talk about yours.
Get in touch →