Self-Evolving Skills: The New Infrastructure for Reliable AI Agents

Most people who build with AI treat skills and prompts as static artifacts. Write it, deploy it, hope it stays good. This is how you build fragile systems that break in production.
The Problem with Static Prompts
The conventional workflow looks like this: craft a skill, test it locally against a few examples, deploy it, and hope. If it starts failing in production, collect feedback, adjust the prompt, redeploy, hope again. You are optimizing blind.
The problem deepens when your skill is doing something that matters. If you are using Claude to summarize regulatory documents, extract data from unstructured PDFs, or support valuation workflows, performance is not just a convenience metric. It is a business metric. Your hourly rate, your client reputation, and your liability surface all depend on the skill staying good.
Static prompts cannot guarantee this. A prompt that works well for 95% of cases will eventually hit an edge case where it fails silently or produces confidently wrong output. You discover this when your client is already relying on the skill.
The Constrained Hill-Climbing Architecture
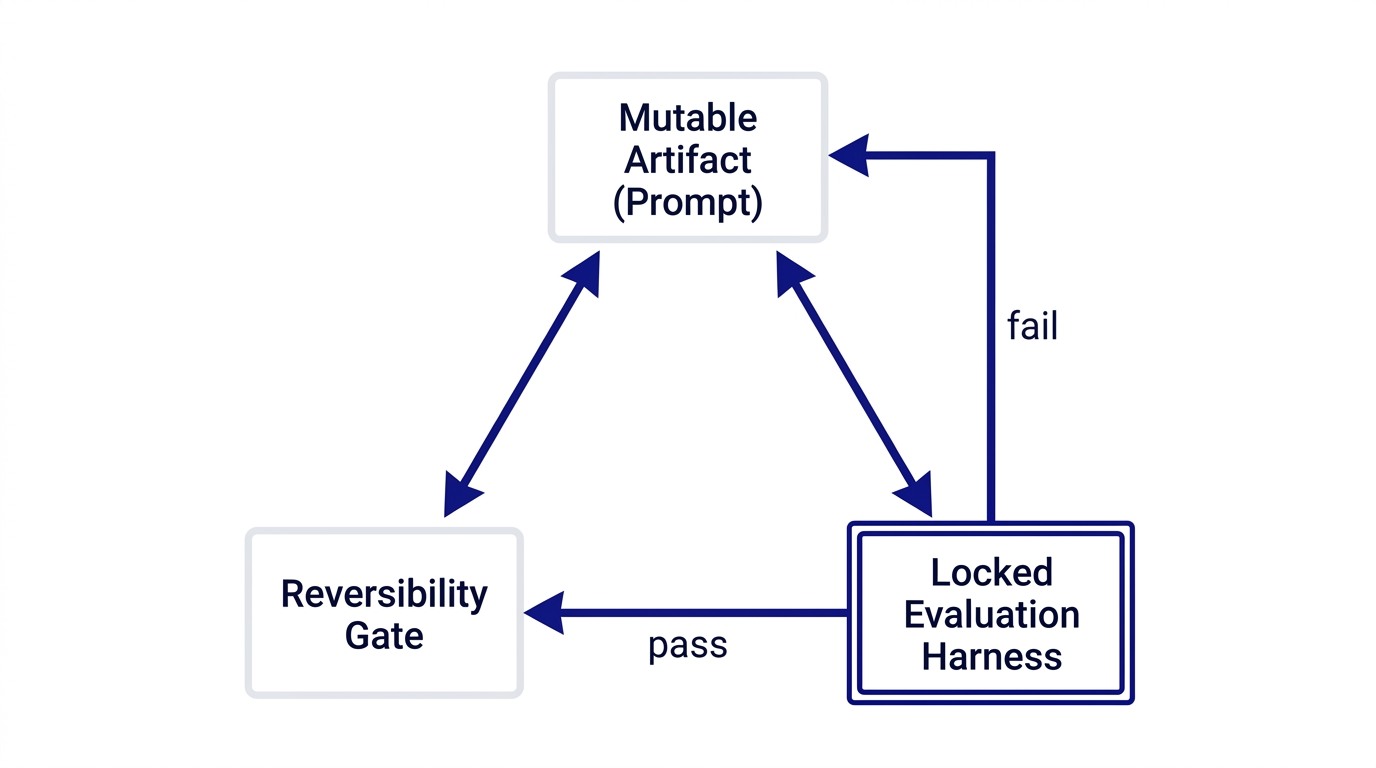
The emerging solution is constrained hill-climbing, and it has three load-bearing parts.
First, a locked evaluation harness. Define 3 to 6 quality criteria that matter for your skill. Yes/no checks that mark success or failure clearly. For a valuation summary skill, that might be: "Does the summary extract the DCF assumptions?" "Is the conclusion aligned with the source document?" "Are there no hallucinated comparable transactions?" Lock this harness. The agent cannot change it.
Second, a mutable artifact. This is the thing the agent can modify. For most skills, it is the prompt itself. The agent makes one small change at a time, commits it, runs the evaluation, and decides whether to keep the change or revert.
Third, reversibility. Every change is isolated and reversible. The agent cannot accumulate bad changes. If a modification drops your pass rate, it reverts automatically. This is the structural difference from human-guided optimization, where we often hold onto partial improvements hoping they will pay off later. The machine does not hope. It measures.
The pattern works because it prevents the most common failure mode of AI optimization: metric gaming. The evaluation stays locked. The agent cannot rewrite the test to pass. It has to actually improve the thing being tested.
How This Works in Practice
Three examples from projects that shipped implementations in the same week make this concrete.
A skills optimizer working on landing page copy started at 56% pass rate on a checklist of criteria: engaging headline, specific benefits, clear CTA, no banned buzzwords. The optimizer ran four rounds:
- Round 1: Added a rule that headlines must include a specific number or technical term. Pass rate jumped to 71%. Kept.
- Round 2: Tightened word count to force brevity. Seemed good, but dropped CTA detail. Pass rate fell to 59%. Reverted.
- Round 3: Added worked examples showing good CTAs from prior outputs. Pass rate to 88%. Kept.
- Round 4: Added specificity rules about what "benefits" means in a SaaS context. Pass rate to 92%. Kept.
Three changes survived. One was reverted. The final prompt was no longer what a human would write by guessing. It was an accumulated artifact of what actually works for that specific task.
An inference speed optimizer on Apple Silicon showed the limits of optimization honestly. The obvious wins came first: argmax sampling instead of temperature-based sampling gave +10.7% throughput. KV cache optimizations gave +2.2%. Then the optimizer hit a wall. Every other change landed in measurement noise or hurt quality. The honest observation: once obvious waste is removed, most parameters are tiny movements around a ceiling imposed by hardware memory bandwidth. You cannot outrun the physics. But you also cannot discover this by reasoning about it in a spreadsheet. You discover it by repeatedly testing, failing to improve, and stopping when gains plateau.
A research team at Hong Kong University built a full platform for self-evolving skills and tested it on 50 real-world professional tasks across six industries: compliance, engineering, legal, tax, accounting, architecture. They measured economic value, not synthetic metrics. Agents using self-evolving skills earned 4.2x more economic value while using 46% fewer tokens. That is not a marginal improvement. That is a category difference.
Why This Matters to You
If you run a one-person company or operate as an embedded executive across multiple roles, your tools need to scale without you scaling with them. This connects directly to what I described in Brief-then-Fire: the goal is to dispatch work that runs independently, not to babysit each output.
Static prompts cannot provide this. A skill that works today but degrades over time, or only works 85% of the time, forces you to manually intervene on every edge case.
Self-improving skills change the calculation. You define what good looks like, lock the evaluation, and let the system gradually improve toward that target. You do not need to be perfect on day one. You need to be measurable from day one.
More importantly, the skill itself becomes an artifact of institutional knowledge. When the optimizer changes a prompt from:
"Extract the key financial metrics"
to:
"Extract the key financial metrics from the DCF model (NPV, WACC, terminal growth rate). If these are not present, explain what is missing."
That change is not arbitrary. It is learned. The system tested both versions and kept the second because it produces more useful output. That knowledge stays in the prompt. It compounds.
This is the same compounding logic that makes The 95% Margin Workflow work over time. Each iteration leaves the system marginally better than it was. The accumulation is the value.
The Broader Pattern
What makes this moment significant is not that self-improving skills are novel. It is that they are converging on the same architecture from five independent directions. When you see that kind of convergence, it usually signals something has moved from research to production.
The skill optimization approach is available as downloadable implementations, cloud platforms, and integration patterns for Claude Code and Cowork. The design pattern is documented. The results are visible.
If you build systems that need to stay reliable at scale, whether that is a consulting practice, a client-facing platform, or an internal operations layer, constrained hill-climbing is the pattern to understand next.
Your alternative is to keep hoping that static prompts stay good over time. Or to manually adjust them every time something breaks. Or to hire someone whose job is to manage the prompts.
Self-improving skills are the infrastructure that lets you choose differently.
Strategy and technology are the same decision. Over 15 years in fintech (CTOS, D&B), prop-tech (PropertyGuru DataSense), and digital startups, I have built frameworks that help founders and executives make both moves at once. Based in Kuala Lumpur.
Working on a 0→1 product?
I help founders and operators go from idea to validated product. Let's talk about yours.
Get in touch →