The Verification Loop: Why AI Skills Without Evals Are Prompts With Delusions of Permanence

The Prompt That Believes in Tomorrow
Six months ago, you built a skill. It worked beautifully. You shipped it, logged the success, moved to the next task. Three months later, you ran it against fresh data. Something was wrong. The tone had drifted. The structure was inconsistent. You did not change the skill. The world did. Or more precisely, the boundary between what the skill was designed for and what you were asking it to do had shifted just enough to expose the silent gap between "seems to work" and "works reliably."
This is the peculiar trap of AI skills without measurement: they accrue the weight of trust without the architecture of reliability. We build skills as if they were tools with permanent form, when they are actually prompts operating inside a black box with no fixed walls. The prompt feels reliable because it worked last time. But confidence without verification is optimism dressed as engineering.
The field has converged on a single insight: the evaluation loop is not optional scaffolding around skill development. It is the mechanism that separates tools from illusions. Multiple independent research teams, isolated from each other, arrived at this conclusion simultaneously. This is rarely accidental.
The Field Converges on Verification
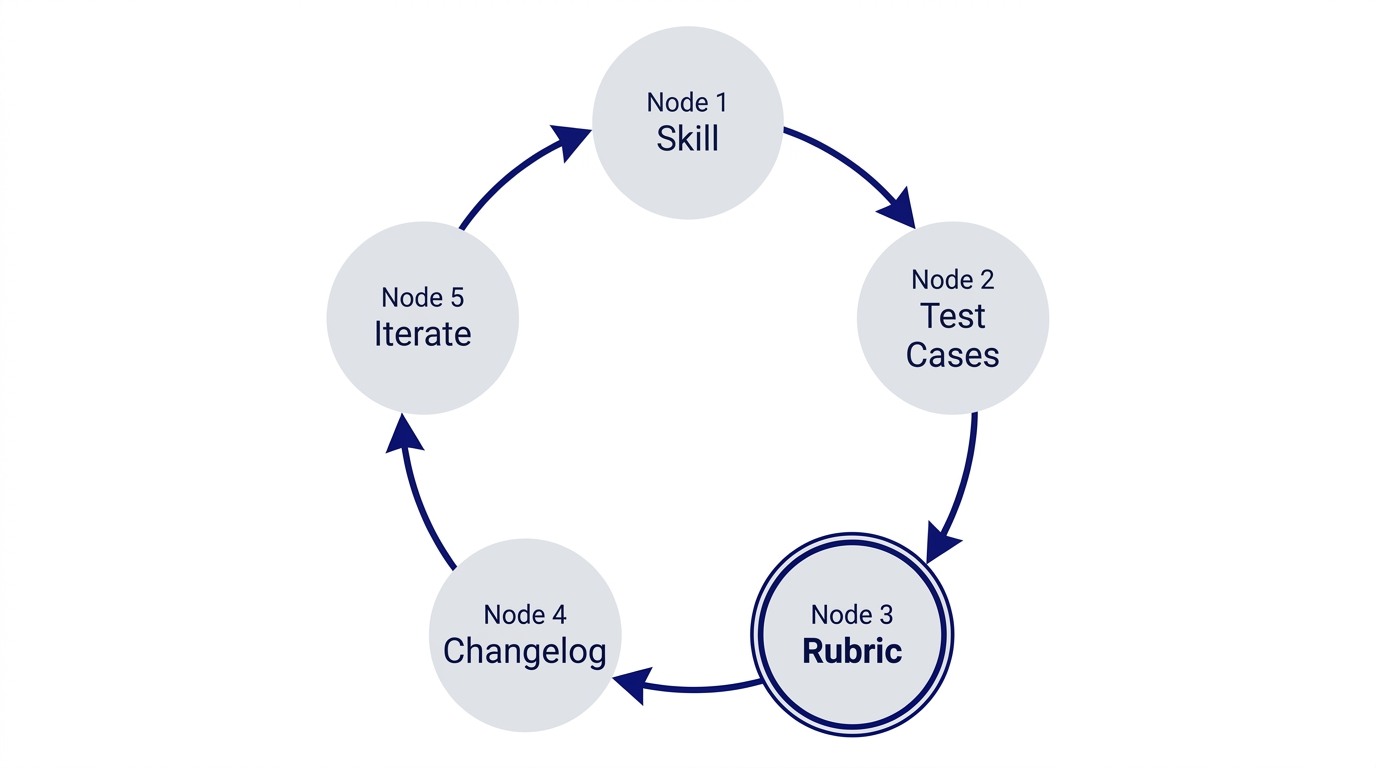
For the past eighteen months, something singular has been emerging across AI research labs, independent practitioners, and engineering teams building production systems: the autoresearch pattern.
Andrej Karpathy described the foundational loop: an agent modifies code, evaluates against fixed benchmarks, keeps improvements, reverts regressions. The agent cannot modify the evaluation itself. The evaluation remains independent, fixed, immutable. This constraint is not a limitation. It is the entire point. The measurement system must be orthogonal to the optimization system, or you have only measured the shape of your own delusion.
That loop descended into a hundred variations. One practitioner built a skill for landing page copy and ran it through structured evaluation. The skill started at 56% pass rate. Four rounds of iteration took it to 92%. Three modifications stayed. One failed and reverted. The most valuable output was not the improved skill. It was the changelog itself. The changelog told you why the improvement happened, which failures got solved, which trade-offs were discovered, which modifications proved fragile.
Independent teams building structured self-critique frameworks took the same verification loop and stripped it to essentials: structured self-critique, measurement against fixed benchmarks, iterative refinement. They outperformed reinforcement learning approaches using nothing more than honest evaluation and honest reversion. No gradient descent. No reward models. No complexity. Just: measure, iterate, verify.
At the same time, practitioners started documenting the pattern. The TDD approach to documentation emerged: run stress tests to discover how AI fails without clear guidance, record the failure patterns, write documentation that directly solves those specific failures, refactor to eliminate excuses for poor performance, verify the fix via adversarial testing. The principle is stark: documentation quality is verifiable. Only validated docs are trustworthy.
This convergence is not incidental. It is how breakthroughs look when they are genuine: isolated teams rediscovering the same principle from different angles, all arriving at the same constraint that reveals value.
Walk the Loop
Now the close view. Watch the mechanism at work.
A landing page copy skill starts with a prompt. It does not specify what makes a headline effective. It does not list the buzzwords that destroy credibility. It does not show worked examples. It is competent generically. It fails specifically.
Run ten pieces of real copy through the skill. Six pass. Four do not. Examine the failures. The headlines are generic. The language leans on buzzwords. The calls-to-action are muted. These are not random defects. They are patterns.
Create an evaluation rubric: headline must contain a specific benefit claim, a banned buzzword list, a worked example showing strong CTA placement. Run the improved skill against the same ten cases. Nine pass. Keep the three modifications that worked. The fourth modification tried, tighter word count, improved the math but starved the call-to-action section. Revert it. The pass rate holds at nine out of ten.
This is not optimization theater. This is debugging. The evaluation rubric is fixed. The skill is not. The skill changes until it reliably clears the rubric. If the world changes later, the rubric will show it first.
The most valuable output is not the improved skill. It is the changelog. The changelog is the evidence that the skill is genuine.
The changelog says: we changed headline rules, this fixed six failures and broke none. We changed the banned word list, this fixed three failures and broke one, so we reverted it. We added examples, the failure count dropped again. This is not marketing copy for the skill. This is the argument for why you should trust it. It is also the diagnostic guide for what to modify if the skill later fails on your data.
Compare this to a skill without evaluation. A prompt with delusions of permanence. You use it. It works. You use it again. You assume this pattern continues. But you are not measuring what works means. You are not recording what fails. You are not iterating on specific failures. You are describing the skill and hoping it stays good forever.
That hope does not age well.
What This Means for One-Person Builders
Return to the macro picture and ask: what changes for someone building AI systems in a one-person company?
You are operating under severe constraints. One set of hands. Limited budget. You cannot afford skills that require constant babysitting. You need them to work, and to keep working, without your intervention. This is not a preference. It is a structural reality.
The verification loop dissolves a false choice. On one side, you want reliable skills that just work without monitoring. On the other, you assume this means building better prompts, better instruction sets, more examples in the system message. That path leads to bloat. Prompts grow. Instruction sets become baroque. The skill becomes harder to maintain, not easier.
The verification loop says: do not improve the prompt. Improve the measurement. Start with the smallest viable skill: a clear instruction, one or two worked examples, a focused objective. Then measure it against real cases from your domain. Identify the specific failures. Do not guess what went wrong. Record what went wrong specifically. Build a rubric that catches these failures. Iterate on the skill until it clears the rubric consistently.
The skill itself may not get much bigger. But its reliability becomes observable. You know what it does well. You know what it fails on. You know what would break it. This knowledge is the difference between a skill you hope works and a skill you know works.
For the one-person company, this is architecture. It is the foundation that prevents you from becoming a full-time babysitter for your own systems. You build verification into the skill from day one. You measure before you iterate. You revert what does not improve the measurement. You document the changelog.
This also means fewer false starts. In many shops, AI skill-building is a fishing expedition: throw a prompt at a problem, see if it sticks, adjust vaguely, ship optimistically, discover failures in production. The verification loop moves the discovery upstream. You catch failures before the skill leaves your hands. You know what trade-offs exist. You have documented the reasoning.
This same discipline applies to how I structure production workflows. See Brief-then-Fire for the pattern of scoping clearly before execution begins, and The 95% Margin Workflow for how verification compounds when you chain skills together.
The Reliability Question
There is a deeper question underneath all of this. When you deploy an AI skill, what are you actually shipping? You are shipping a decision rule. You are saying: given this input, this rule will produce reliable output. Not sometimes. Reliably.
Reliability without measurement is confidence. Confidence without evidence is faith. Faith does not scale.
The verification loop asks you to change that statement. It asks you to say: given this input, this rule will produce reliable output, and here is the evidence. Here is the evaluation rubric. Here is the changelog showing what we modified and why. Here is the adversarial test showing where it still fails. Here is the boundary between the problem we solved and the problems we left unsolved.
That is what permanence actually looks like. Not a prompt that works today. A skill that works today and fails in documented, specific ways, and can be repaired because we know exactly where the cracks are.
The question is not whether you will eventually need this. You will. The question is whether you will build it in from the start, or discover it too late, after you have already shipped systems you cannot maintain.
The loop works. The only remaining choice is yours.
Strategy and technology are the same decision. Over 15 years in fintech (CTOS, D&B), prop-tech (PropertyGuru DataSense), and digital startups, I have built frameworks that help founders and executives make both moves at once. Based in Kuala Lumpur.
Working on a 0→1 product?
I help founders and operators go from idea to validated product. Let's talk about yours.
Get in touch →